Cloud-Sicherheit ist nichts Neues. Tatsächlich gibt es sie schon seit etlichen Jahren.
Doch mit jedem Jahr, das vergeht, wird die Cloud komplexer, und mit dieser Komplexität entstehen neue Risiken.
Vor zehn Jahren ging es in der Cloud nur um Speicher und Rechenleistung. Doch heute werden APIs, Identitäten, KI-Workloads und ganze Unternehmen in der Cloud aufgebaut. Dies zeigt, dass die Angriffsfläche nie schrumpft; sie wächst stetig weiter.
Doch trotz allem behandeln viele Organisationen die Cloud-Sicherheit immer noch wie eine Checkliste. Es läuft ungefähr so ab: Dies verschlüsseln. MFA hinzufügen. Ab und zu einen Scan durchführen.
Dabei wissen Sie, wie ich, dass es nur einer Fehlkonfiguration bedarf, die durchrutscht. Einer Berechtigungsausweitung. Einer Instanz von Shadow IT, die sich einschleicht. Und das ist alles, was ein Angreifer braucht, um eine Lücke zu finden.
Eine Möglichkeit, nicht in diese Falle zu tappen, besteht darin, Best Practices für die Cloud-Sicherheit zu befolgen. Nicht nur als Klischee, sondern als grundlegenden Ansatz für den Aufbau und die Pflege einer sicheren Cloud-Umgebung.
In diesem Artikel erfahren Sie 25 Best Practices für die Cloud-Sicherheit, die jede Organisation befolgen sollte, um Bedrohungen einen Schritt voraus zu sein und Ihre Daten, Anwendungen und Benutzer zu schützen.
Doch zunächst wollen wir verstehen, warum Cloud-Sicherheit sowohl wichtig als auch herausfordernd ist.
Warum ist Cloud-Sicherheit wichtig und herausfordernd?
Der Wechsel von On-Premises zur Cloud hat alles verändert. Plötzlich konnten Teams die benötigte Hardware in Minuten statt in Monaten erhalten, und das fast ohne Vorabkosten. Obwohl diese Geschwindigkeit Innovationen ermöglichte, eröffnete sie auch neue Risiken.
In den On-Premises-Zeiten hatten Sicherheitsteams die volle Kontrolle über physische Server, Netzwerke und den Zugriff. In der Cloud ist diese Kontrolle jedoch geteilt.
Ingenieure können Ressourcen mit wenigen Klicks bereitstellen, und Workloads laufen über Regionen, Konten und sogar Anbieter hinweg. Diese Art der Demokratisierung ist mächtig, bedeutet aber auch, dass die Angriffsfläche breiter ist als je zuvor. Und denken Sie daran: Cloud-Sicherheit basiert auf dem Modell der geteilten Verantwortung.
Die eigentliche Herausforderung ergibt sich aus zwei Dingen: Skalierung und Komplexität. Sie sichern nicht länger eine feste Umgebung. Im großen Maßstab sichern Sie Hunderte von ephemeren Containern, Serverless Functions und Diensten, die minütlich gestartet und heruntergefahren werden.
Wenn man nun Compliance-Anforderungen, Multi-Cloud-Umgebungen und den ständigen Druck, schneller zu liefern, hinzunimmt, ist es nicht schwer zu erkennen, warum Cloud-Sicherheit sowohl entscheidend als auch schwierig umzusetzen ist.
Cloud-Sicherheit: Best Practices für Governance und Verantwortung
Wenn es um Cloud-Sicherheit geht, ist Verwirrung einer Ihrer größten Feinde. Wenn niemand weiß, wer wofür zuständig ist, entstehen Lücken. Deshalb sind Governance und Verantwortung die ersten Best Practices, die man richtig umsetzen muss.
1. Das Modell der geteilten Verantwortung über den Cloud-Anbieter hinaus verstehen
Das Modell der geteilten Verantwortung ist nicht universell anwendbar; es hängt von der Art der verwendeten Cloud-Umgebung ab. Zum Beispiel trägt eine Organisation, die ein IaaS-Setup betreibt, wesentlich mehr Verantwortung als ein sechs Monate altes KI-Startup, das auf FaaS aufbaut.
Die Abbildung unten, vom Center for Internet Security (CIS), veranschaulicht das Verantwortungsniveau eines Cloud-Kunden.

Über die obige Abbildung hinaus ist es wichtig, sich daran zu erinnern, dass Sicherheitsvorfälle nicht isoliert auftreten. Das bedeutet, dass Cloud-Sicherheit nicht nur „die Aufgabe des Sicherheitsteams“ ist. Es ist eine gemeinsame Anstrengung von Engineering, Operations und der Führungsebene.
Wie lässt sich also dieses Modell der geteilten Verantwortung umsetzen, ohne dass es zu einem Schuldzuweisungsspiel wird?
Die Antwort lautet...Trommelwirbel...„Shift Left“.
Vielleicht haben Sie es erraten, vielleicht auch nicht. Unabhängig davon ist „Shift Left“ mehr als nur ein Schlagwort. Der Code, den Entwickelnde schreiben, die Infrastruktur und alles dazwischen sind potenzielle Angriffsvektoren und machen für einen böswilligen Akteur keinen Unterschied.
Anstatt sich also erst zur Laufzeit um Sicherheit zu kümmern, sollten Sie bereits ab der ersten Codezeile damit beginnen.
Sollten in irgendeiner Phase des Software Development Lifecycle (SDLC) Vorfälle auftreten, erweist sich das SRE-Konzept eines blameless Postmortem als nützlich, um aus diesem Fehler zu lernen.
Best Practices zur Umsetzung:
- Informieren Sie sich über die spezifischen Verantwortlichkeiten Ihres Cloud-Anbieters und verstehen Sie, was Sie in Ihrer Art von Cloud-Umgebung selbst verantworten.
- Verlagern Sie die Sicherheit nach links, indem Sie Entwickelnde mit entwicklerzentrierten Sicherheitstools ausstatten, die sich direkt in ihren Workflow integrieren lassen und vor Anti-Patterns, anfälligen Abhängigkeiten und hartkodierten Secrets schützen, die in Versionskontrollsysteme gelangen.
- Nutzen Sie die Idee von blameless Postmortems, um aus Vorfällen zu lernen, ohne Schuldzuweisungen zu machen.
- Setzen Sie Leitplanken mit Policy-as-Code-Tools durch. Keine Sorge, wir werden diese Empfehlungen später in diesem Artikel ausführlicher behandeln.
2. Sicherheit mit Compliance-Vorgaben integrieren
Man kann Governance nicht erwähnen, ohne ihren Kompagnon zu nennen: Compliance. Die beiden gehen Hand in Hand. Governance legt die Spielregeln fest, und Compliance stellt sicher, dass man sich daran hält.
Das Problem ist jedoch, dass viele Organisationen Compliance als reine Papierübung betrachten. Vielleicht tun Ihre das auch.
Audit bestehen, Abzeichen erhalten und weitermachen.
Diese Denkweise ist gefährlich. Compliance-Frameworks wie die DSGVO oder PCI DSS sind nicht nur Hürden, die es zu überwinden gilt; sie sind Leitplanken, die dazu dienen, sensible Daten zu schützen und Risiken zu mindern. Richtig umgesetzt verbessern sie Ihre grundlegende Sicherheitslage. Falsch umgesetzt ist es eine vergebliche Mühe.
Best Practices zur Umsetzung:
Der Schlüssel liegt darin, Compliance in die täglichen Workflows zu integrieren. Dabei werden dieselben Tools verwendet, die Sie bereits zur Sicherung Ihrer Infrastruktur einsetzen. Einige Lösungen unterstützen Sie, indem sie Code- und Cloud-Sicherheitskontrollen für ISO 27001, SOC 2 Type 2, PCI, DORA, NIS2, HIPAA & mehr automatisieren.
Cloud-Sicherheit: Best Practices für Identity & Access Management
Nachdem wir die Best Practices für Governance behandelt haben, widmen wir uns einem der herausforderndsten Aspekte der Cloud-Sicherheit: der Verwaltung von Identitäten und Zugriffen.
3. Das Prinzip der geringsten Rechte befolgen
Der erste Schritt zur effektiven Verwaltung des Identitätszugriffs besteht darin, sicherzustellen, dass jede Identität nur auf das zugreifen kann, was sie benötigt, und nicht mehr. Dies ist das, was das Prinzip der geringsten Rechte (PoLP) fördert.
Es ist wichtig zu beachten, dass PoLP auch für nicht-menschliche Identitäten wie APIs, Service-Accounts, Container, Serverless Functions usw. gelten sollte, die oft aus Bequemlichkeit mit übermäßig weitreichenden Berechtigungen ausgeführt werden.
Bei Kompromittierung können diese Berechtigungen genauso leicht missbraucht werden wie ein menschliches Admin-Konto. Durch die Anwendung von PoLP auf Menschen und Workloads verringern Sie den potenziellen Schaden (Blast Radius) eines jeden Verstoßes.
Best Practices zur Umsetzung:
- Standardmäßig „alles verweigern“, dann nur die minimal erforderlichen Aktionen gewähren.
- Ersetzen Sie Wildcards (s3:*) durch explizite Aktionen (z. B. s3:GetObject, s3:PutObject).
- Prüfen und entfernen Sie regelmäßig ungenutzte Berechtigungen aus IAM-Rollen und Service-Accounts. Anstatt einer Lambda-Funktion beispielsweise AmazonS3FullAccess zu gewähren, hängen Sie eine Benutzerdefinierte IAM-Richtlinie an, wie:
{
"Version": "2012-10-17",
"Statement": [
{ "Effect": "Allow",
"Action": ["s3:GetObject", "s3:PutObject"],
"Resource": "arn:aws:s3:::my-app-bucket/*"
}
]
}Dies stellt sicher, dass die Funktion nur in den einen Bucket lesen und schreiben kann, den sie tatsächlich benötigt, und nichts anderes.
4. Multi-Faktor-Authentifizierung (MFA) verwenden
Auch wenn jede Identität nur den Zugriff hat, den sie benötigt, ist es dennoch wichtig, eine Multi-Faktor-Authentifizierung zu implementieren, insbesondere für Admin- und kritische Konten. MFA fügt eine zweite Schutzschicht über den Anmeldeinformationen hinzu.
Die meisten Multi-Faktor-Authentifizierungen verwenden heute eine E-Mail-basierte Authentifizierung. Obwohl dies wie beabsichtigt eine zusätzliche Sicherheitsebene hinzufügt, sind sie leicht anfällig für Phishing.
Best Practices zur Umsetzung:
- Bei der Implementierung von MFA sollten Sie Optionen wählen, die vor Phishing und anderen Cyberangriffen schützen, wie z. B. YubiKeys. Diese Lösungen bieten eine physische schlüsselbasierte MFA, die einen Angreifer dazu zwingen würde, den Schlüssel physisch zu stehlen.
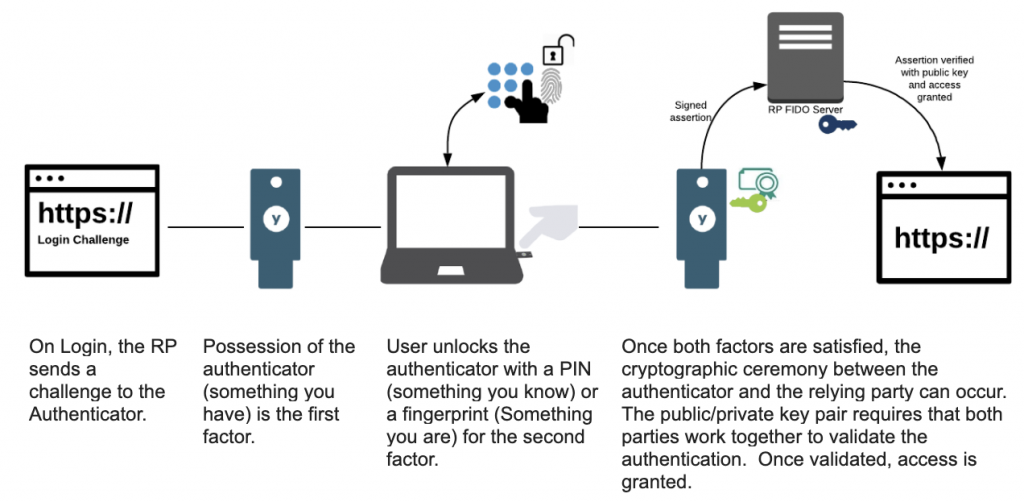
- Integrieren Sie Hardware-Schlüssel mit Ihrem SSO-Anbieter (Okta, Azure AD, Google Workspace) für eine nahtlose Einführung.
- Schreiben Sie eine Multi-Faktor-Authentifizierung für risikoreiche Aktionen vor (z. B. Zugriff auf die Produktionsumgebung, Ändern von IAM-Richtlinien).
- Prüfen Sie regelmäßig die MFA-Registrierung, um sicherzustellen, dass alle Konten (einschließlich Auftragnehmer) abgedeckt und bei Änderungen des Geschäftskontexts angepasst werden.
5. Mit Richtlinien über RBAC hinausgehen
RBAC und herkömmliche IAM-Tools allein lösen die Herausforderungen bei der Verwaltung von Identitäten in Cloud-nativen Umgebungen nicht, sei es in der Cloud, im Cluster, im Container oder auf der Code-Ebene, insbesondere für nicht-menschliche Identitäten wie Service-Accounts, API-Schlüssel, Zertifikate und Secrets.
Gute Cloud-native Sicherheitspraktiken erfordern den Einsatz von Policy as Code (PaC), um dynamische, fein granulierte Berechtigungen durchzusetzen, die auf spezifische Szenarien zugeschnitten sind.
Zusammen schaffen sie eine mehrschichtige Zugriffsstrategie:
- RBAC definiert das Wer und Was.
- PaC definiert das Wann, Wie und unter welchen spezifischen Bedingungen.
Zum Beispiel kann ein Ingenieur mit der Rolle Platform Admin (RBAC) in die Staging-Umgebung deployen. Eine PaC-Regel blockiert das Deployment jedoch, wenn das Image nicht gescannt wurde, der Branch nicht signiert ist oder es außerhalb der Geschäftszeiten liegt.
Diese Kombination erzwingt das Prinzip der geringsten Rechte im großen Maßstab, verhindert Fehltritte und macht Sicherheit wiederholbar, testbar und auditierbar.
Best Practices zur Umsetzung:
Wenn Sie die AWS Cloud nutzen, bietet deren Ökosystem Tools für die proaktive, präventive, detektive und reaktive Richtlinienimplementierung. Sie sollten diesen praktischen Leitfaden für den Einstieg in Policy as Code auf AWS lesen.
Andere Cloud-Service-Provider wie Azure bieten ebenfalls Policy as Code Tools an. Sie können auch Open-Source-PaC-Tools wie Open Policy Agent (OPA) und Kyverno in Betracht ziehen, die standardmäßig plattformunabhängig und „Cloud-nativ“ sind.
6. Schlüssel und Anmeldeinformationen regelmäßig rotieren
Viele warten, bis es zu einem Einbruch kommt, bevor sie Schlüssel ändern. Das sollten Sie nicht tun. Sie sollten Schlüssel automatisch und regelmäßig rotieren.
Wie oft ist „regelmäßig“? Monatlich, vierteljährlich oder jährlich? Der CIS AWS Foundations Benchmark empfiehlt alle 90 Tage oder weniger.
In komplexen Umgebungen ist weniger mehr bei der Schlüsselrotation, insbesondere für nicht-menschliche Identitäten. Ein häufigeres Automatisieren dieser Schlüssel reduziert das Risiko einer Sicherheitsverletzung erheblich, falls ein Schlüssel jemals kompromittiert wird, da diese Arten von Identitäten in den meisten Fällen wenig bis keine Sichtbarkeit haben.
Best Practices zur Umsetzung:
- Ersetzen Sie statische Anmeldeinformationen durch kurzlebige Tokens (z. B. AWS STS, GCP Workload Identity, Azure Managed Identities).
- Speichern und rotieren Sie Secrets mithilfe eines zentralen Managers (AWS Secrets Manager, HashiCorp Vault, Azure Key Vault) anstelle von Code- oder Konfigurationsdateien.
- Überwachen Sie Protokolle (CloudTrail, Audit Logs, Azure Monitor) auf ungewöhnliche Nutzung von Anmeldeinformationen nach der Rotation.
- Prüfen Sie unbenutzte und exponierte Schlüssel und widerrufen Sie diese sofort. Live-Secret-Detection-Tools helfen Ihnen, aktive Secrets und deren potenzielle Risiken zu finden.
7. Just-in-Time (JIT) Zugriff nutzen
Es gibt Situationen, in denen ein Cloud-Benutzer mit minimalem Zugriff erhöhte Berechtigungen benötigt, um seine Arbeit zu erledigen. Anstatt den Standardzugriff dieses Benutzers zu erhöhen, sollten Sie Just-in-Time (JIT) Zugriff implementieren, um eine temporäre Berechtigungserhöhung anstelle von dauerhaften Berechtigungen zu gewähren.
Best Practices zur Umsetzung:
- Eine Entwickelnde wird eine Rolle mit den erforderlichen Berechtigungen anfordern, mit:
- Okta Access Requests und AWS IAM Identity Center auf AWS
- Just-in-Time-Maschinenzugriff auf Azure
- Privileged Access Manager auf Google Cloud oder andere externe Tools
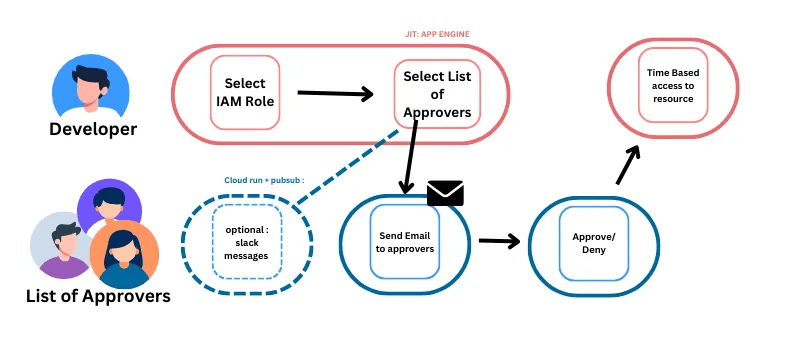
- Legen Sie immer Zeitlimits (z. B. 30 Minuten, 1 Stunde, 1 Tag) für erhöhte Sitzungen fest; keine unbefristeten Genehmigungen.
- Fordern Sie eine MFA-Re-Authentifizierung an, bevor JIT-Zugriff gewährt wird.
- Protokollieren und überwachen Sie alle JIT-Anfragen und -Genehmigungen für die Auditierbarkeit.
Cloud-Sicherheit: Best Practices für den Datenschutz
Daten sind das Lebenselixier jedes Unternehmens. Wenn Sie sich tatsächlich zwischen einer Sicherheitsverletzung auf Ihren Servern oder einer Sicherheitsverletzung in Ihrer Datenbank entscheiden müssten, würden Sie immer Ihre Server wählen. So wertvoll sind Ihre Daten für Sie.
Wie sichern Sie also Ihre Daten in der Cloud?
8. Daten während der Übertragung und im Ruhezustand verschlüsseln
Ob im Ruhezustand oder während der Übertragung, Sie sollten Ihre Cloud-Daten verschlüsseln. Im Ruhezustand verwenden Sie starke, moderne Verschlüsselungsalgorithmen wie AES-256 oder TDE (Transparent Data Encryption). Dies stellt sicher, dass die Daten selbst bei einem Zugriff eines Angreifers auf den zugrunde liegenden Speicher ohne die notwendigen Verschlüsselungsschlüssel unlesbar bleiben.
Für Daten während der Übertragung sollte die gesamte Kommunikation, einschließlich API-Aufrufen und Inter-Service-Traffic, mittels Protokollen wie TLS/SSL gesichert werden. In einer Zero-Trust-Umgebung sollten Sie Mutual TLS (mTLS) implementieren, da es sicherstellt, dass die Workloads/Identitäten an jedem Ende einer Netzwerkverbindung die sind, für die sie sich ausgeben, indem überprüft wird, dass beide den korrekten privaten Schlüssel besitzen.
Die Cloud-Datenverschlüsselung basiert auf einem robusten Key Management System (KMS). Ihr KMS sollte ein sicherer, zentralisierter Dienst zum Generieren, Speichern, Verwalten und Rotieren von Verschlüsselungsschlüsseln sein.
Best Practices zur Umsetzung:
- Verschlüsseln Sie alle Speichervolumes, Datenbanken und Objektspeicher (z. B. AWS S3 SSE, Azure Storage Service Encryption, GCP CMEK).
- Erzwingen Sie TLS 1.2+ für alle API-Endpunkte und den Inter-Service-Traffic.
- Implementieren Sie mTLS für interne Microservices, um Identitätsdiebstahl zu verhindern.
- Zentralisieren Sie die Schlüsselverwaltung mit einem verwalteten KMS (AWS KMS, Azure Key Vault, GCP KMS, HashiCorp Vault).
- Automatisieren Sie die Schlüsselrotation und überwachen Sie die unautorisierte Schlüsselnutzung.
Das untenstehende Kubernetes Ingress-Snippet erzwingt mTLS, indem es von Clients verlangt, ein gültiges Zertifikat von einer vertrauenswürdigen CA (client-ca) vorzulegen, bevor sie auf den Dienst zugreifen können.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: app-ingress-mtls
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/auth-tls-secret: "prod/client-ca" # Client-CA-Zertifikat
nginx.ingress.kubernetes.io/auth-tls-verify-client: "on" # Client-Zertifikat erforderlich
spec:
tls:
- hosts:
- secure.example.com
secretName: secure-app-tls
rules:
- host: secure.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: app
port:
number: 80
9. Daten sichern und Wiederherstellung testen
Es gibt im Wesentlichen zwei goldene Regeln für die Datensicherung: die 3-2-1-Regel und die 3-2-1-1-0-Regel.
3-2-1 empfiehlt:
- 3 = Halten Sie drei Kopien Ihrer Daten vor
- 2 = Verwenden Sie zwei verschiedene Arten von Speichermedien
- 1 = Speichern Sie eine Kopie extern
3-2-1-1-0 baut auf 3-2-1 auf, um sich vor modernen Bedrohungen zu schützen, und empfiehlt Ihnen:
- 3 = Halten Sie drei Kopien Ihrer Daten vor
- 2 = Verwenden Sie zwei verschiedene Arten von Speichermedien
- 1 = Speichern Sie eine Kopie extern
- 1 = Speichern Sie eine Kopie offline oder unveränderlich
- 0 = Stellen Sie sicher, dass keine Backup-Fehler auftreten
Die Hauptfrage ist nicht, ob Sie Backups erstellen, sondern ob Sie mit diesen Backups eine Wiederherstellung durchführen können. Viele Teams gehen davon aus, dass Backups sicher sind, bis eine Katastrophe eintritt, nur um dann festzustellen, dass Dateien beschädigt sind, Daten fehlen oder Wiederherstellungsprozesse Tage statt Stunden dauern.
Das Testen von Backups mag unnötig erscheinen, wenn alles reibungslos läuft, aber Ausfälle passieren nicht nach Plan.
Stellen Sie sich Ihren Puls vor, wenn Sie versuchen, während eines größeren Ausfalls mit einem getesteten Backup im Vergleich zu einem ungetesteten Backup wiederherzustellen.
Best Practices zur Umsetzung:
- Verschlüsseln Sie Backups im Ruhezustand und während der Übertragung.
- Führen Sie regelmäßige Wiederherstellungsübungen durch, um Wiederherstellungspunktziele (RPO) und Wiederherstellungszeitziele (RTO) zu etablieren und zu validieren.

- Dokumentieren Sie Wiederherstellungsverfahren, damit diese unter Druck ausgeführt werden können.
- Alte Backups rotieren und bereinigen, um die Angriffsfläche und Kosten zu reduzieren.
Sie sind startklar!!
10. Sensible Daten klassifizieren und kennzeichnen
Man kann nicht schützen, was man nicht kennt. In den meisten Cloud-Umgebungen sind sensible Daten über S3-Buckets, Datenbanken, Message Queues und sogar Logs verteilt. Ohne eine ordnungsgemäße Klassifizierung ist es unmöglich, die richtigen Kontrollen anzuwenden.
Durch das Tagging und die Kennzeichnung von Daten basierend auf ihrer Sensibilität – öffentlich, intern, vertraulich, eingeschränkt – schaffen Sie Transparenz und setzen skalierbare Leitplanken durch.
Viele Cloud-Anbieter unterstützen integrierte Klassifizierungstools (z. B. AWS Macie, Azure Information Protection, GCP DLP). Sobald Daten gekennzeichnet sind, können Sie Verschlüsselung, Zugriffsbeschränkungen und Überwachung automatisch durchsetzen.
Best Practices zur Umsetzung:
- Speicher-Buckets und Datenbanken nach PII, Anmeldeinformationen und Finanzdaten scannen.
- Metadaten-Tags oder -Labels (z. B. sensitivity=confidential) anwenden, um Richtlinien auszulösen.
- Klassifizierung mit Cloud-nativen Tools oder Scannern von Drittanbietern automatisieren.
- Den Zugriff auf „eingeschränkte“ Datenklassen auf genehmigte Rollen beschränken.
11. Tokenisierung und Anonymisierung anwenden
Manchmal bedeutet der Schutz von Daten, diese so zu transformieren, dass sie im Falle eines Lecks nutzlos sind. Tokenisierung ersetzt sensible Felder (wie Kreditkartennummern) durch nicht-sensible Platzhalter, während Anonymisierung identifizierende Informationen vollständig aus Datensätzen entfernt. Beide Ansätze reduzieren die Exposition, ohne Geschäftsabläufe zu unterbrechen.
Diese Techniken sind besonders kritisch in Umgebungen, in denen Entwickelnde, Analysten oder Drittparteien Zugriff auf Datensätze benötigen, ohne die rohen sensiblen Werte zu sehen. Richtig angewendet, ermöglichen Tokenisierung und Anonymisierung ein Gleichgewicht zwischen Sicherheit und Benutzerfreundlichkeit.
Best Practices zur Umsetzung:
- Zahlungsdetails vor der Speicherung tokenisieren. Sie können einen PCI-konformen Vault verwenden.
- Anonymisierung für Analyse-Datensätze anwenden, indem PII (z. B. Namen, E-Mails) maskiert werden.
- Format-erhaltende Tokenisierung verwenden, damit Systeme Datenformate weiterhin validieren.
- Transformationen an Ingestion-Punkten automatisieren, um sicherzustellen, dass Rohdaten niemals in Logs oder nicht-sichere Systeme gelangen.
Cloud-Sicherheit Netzwerk- & Infrastruktur-Best Practices
Um sichere und zuverlässige Systeme aufzubauen, müssen Organisationen das Fundament ihrer Cloud-Umgebungen stärken. Dies bedeutet die Einführung von Best Practices für Netzwerkdesign, Konnektivität und Infrastrukturmanagement.
So gehen Sie vor:
12. Netzwerksegmentierung implementieren
Flache Netzwerke sind anfällig. Wenn jede Ressource in Ihrer Cloud im selben Netzwerk liegt, ermöglicht eine Kompromittierung einer Ressource Angreifern freien Zugriff auf Ihre gesamte Cloud. Deshalb sollten Sie Netzwerksegmentierung für Ihre Cloud-Sicherheitsstrategie implementieren.
Best Practices zur Umsetzung:
Das Ziel ist Microsegmentierung. Die Isolierung von Workloads basierend auf ihrer Sensibilität und Funktion erzwingt Zero-Trust, wobei jede Verbindung als potenzielle Bedrohung behandelt wird. Dies erreichen Sie mit Tools wie Network Security Groups, privaten VLANs und internen Firewalls.
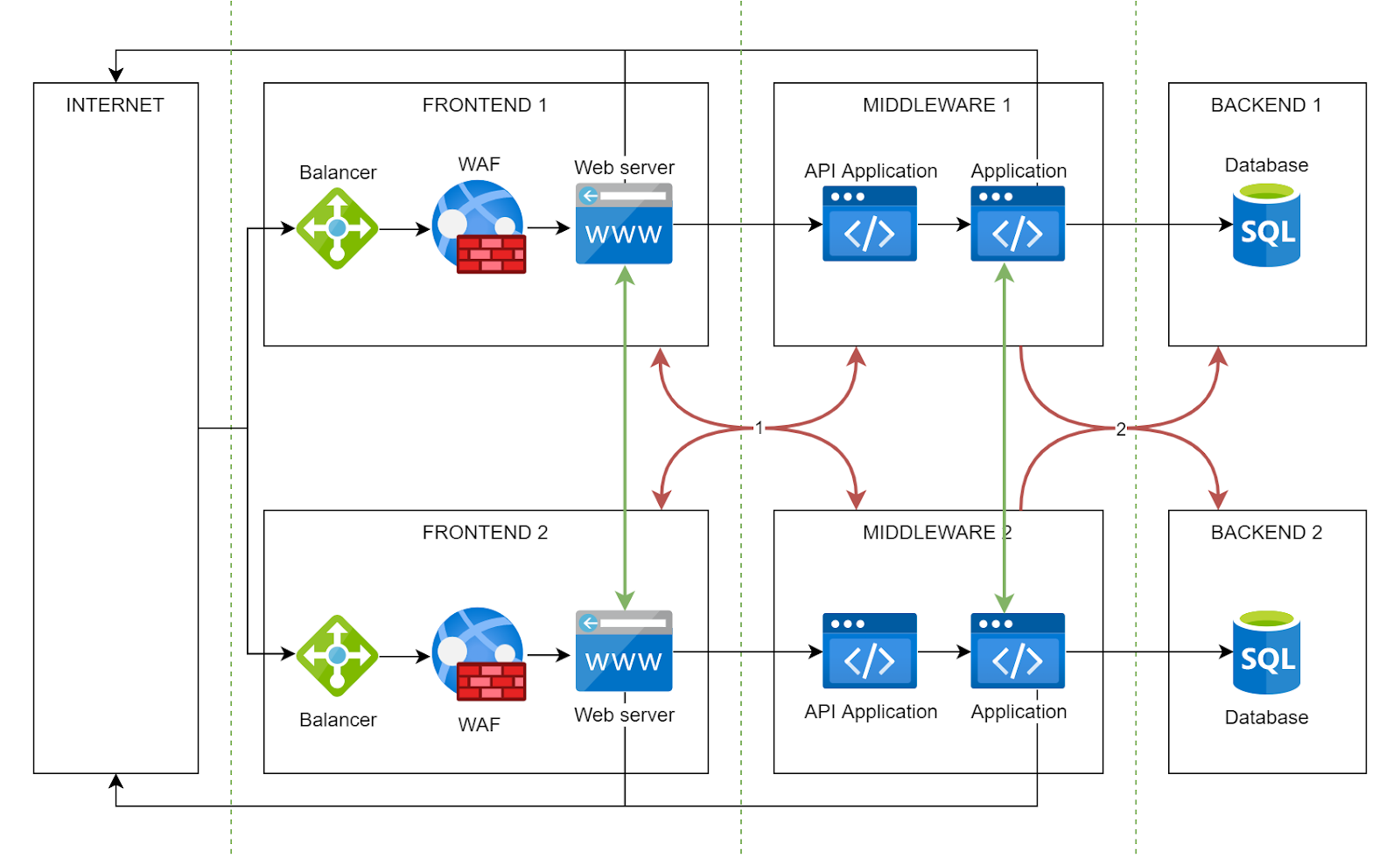
In der obigen Abbildung der Netzwerksegmentierung besteht Internetzugriff in den FRONTEND- und MIDDLEWARE-Segmenten, der Zugriff zwischen den FRONTEND- und MIDDLEWARE-Segmenten verschiedener Informationssysteme ist jedoch untersagt.
Diese Basisschicht stellt sicher, dass selbst bei Ausnutzung einer Fehlkonfiguration oder Schwachstelle in MIDDLEWARE 1 der Auswirkungsbereich minimal ist, wodurch andere MIDDLEWARES geschützt werden.
13. API-Endpunkte absichern
APIs sind das Nervensystem von Cloud-Anwendungen. Und der schnellste Weg, einen Organismus (in diesem Fall Anwendungen) zu töten, ist, sein Nervensystem anzugreifen.
Es hat oberste Priorität sicherzustellen, dass alle APIs in Ihrer Umgebung über ordnungsgemäße Authentifizierungs- und Autorisierungsmechanismen verfügen, damit Bedrohungsakteure sie nicht ausnutzen können, um unbefugten Zugriff zu erlangen oder Dienste zu stören.
Best Practices zur Umsetzung:
- Platzieren Sie alle externen APIs hinter einem Gateway (Kong/Apigee/AWS API Gateway) mit routenspezifischen Richtlinien.
- OAuth2/OIDC vorschreiben; kurzlebige Scopes mit geringsten Berechtigungen ausstellen (keine Wildcard-Claims).
- Ratenbegrenzungen/Kontingente pro API-Schlüssel/Client anwenden und strengere Begrenzungen für ressourcenintensive Routen festlegen.
- TLS 1.2+ überall aktivieren; mTLS für interne Microservice-Aufrufe verwenden.
- APIs automatisch erkennen und taggen; undokumentierte und veraltete Versionen blockieren oder außer Betrieb nehmen.
- API-Logs an Ihr SIEM senden; bei 401/403-Spitzen, ungewöhnlichen Datenabrufen oder Enumerationsmustern alarmieren.
- Und vergessen Sie nicht, Ihre APIs regelmäßig auf Schwachstellen und Fehler zu scannen.
Wie bereits erwähnt, ist API-Sicherheit ein Kernbestandteil Ihrer Cloud-Sicherheitsstrategie. Für weitere Anleitungen und praktische Tutorials lesen Sie unsere anderen Blogbeiträge:
- API-Sicherheitstests: Tools, Checklisten & Bewertungen
- API Security Best Practices & Standards
- Die besten API-Scanner im Jahr 2025
- Die Zukunft der API-Sicherheit: Trends, KI & Automatisierung
14. Container absichern
Jede Organisation möchte die Vorteile von Cloud-Native nutzen. Aber sind sie auch bereit für die Herausforderungen? Sind Sie bereit?
Container sind das Rückgrat der Cloud-nativen Infrastruktur, bringen aber auch einzigartige Risiken mit sich. Fehlkonfigurationen, anfällige Basis-Images und übermäßige Berechtigungen können Angreifern Tür und Tor öffnen.
Das Gute ist, dass die meisten Containersicherheitsrisiken und -probleme durch Befolgen der empfohlenen Best Practices behoben werden können.
Best Practices zur Umsetzung:
- Verwenden Sie immer minimale, verifizierte Basis-Images (z. B. Distroless, Alpine) aus vertrauenswürdigen Quellen. Verwenden Sie spezifische Image-Versionen.
- Unnötige Linux-Capabilities entfernen (CAP_SYS_ADMIN ist fast immer ein Warnsignal).
- Führen Sie Container niemals als Root aus; falls in einem Ausnahmefall ein Container Root-Zugriff benötigt, ordnen Sie die Container-UID einem weniger privilegierten Benutzer auf dem Host neu zu.
- Überwachen Sie Laufzeitaktivitäten, um abnormales Verhalten in Echtzeit zu erkennen und darauf zu reagieren.
- Scannen Sie Images und deren Repositorys automatisch, um Schwachstellen zu finden und zu beheben, die in den Open-Source-Paketen Ihrer Basis-Images und Dockerfiles verwendet werden.
Angenommen, Sie verwenden Kubernetes zur Orchestrierung Ihrer Container. In diesem Fall können Sie Admission Controller konfigurieren, um Anfragen an den API-Server, z. B. eine Bereitstellung, abzufangen und zu validieren, dass bestimmte Sicherheitsbedingungen vor der Bereitstellung erfüllt sind.
15. Sichere Konfigurations-Baselines einführen
Standardeinstellungen sind auf Bequemlichkeit, nicht auf Sicherheit ausgelegt. Um Ihre Infrastruktur sicher zu halten, sichern Sie das Betriebssystem, die Container-Laufzeitumgebung und die Cloud-Dienste mit vordefinierten Baselines ab, damit Sie das Hardening nicht in jedem Sprint neu erfinden müssen.
Best Practices zur Umsetzung:
- Beginnen Sie mit den CIS-Benchmarks (spezifische Betriebssysteme, Kubernetes, Docker, Cloud-Anbieter) und behandeln Sie diese wie Code: versioniert, geprüft und durch Infrastructure as Code (IaC) erzwungen.
- Erzwingen Sie Konfigurationen mit Policy-as-Code, wie bereits erwähnt (OPA, Kyrveno, Terraform Sentinel, Azure/AWS/GCP Policy).
- Aktivieren Sie sichere Standardeinstellungen: SSH-Hardening, auditd, Kernel-Parameter, Container ohne Root-Rechte, schreibgeschützte Dateisysteme.
Wenn all dies eingerichtet ist, erkennen Sie kontinuierlich Fehlkonfigurationen, Schwachstellen und Richtlinienverstöße in all Ihren Clouds und beheben Sie diese schnell.
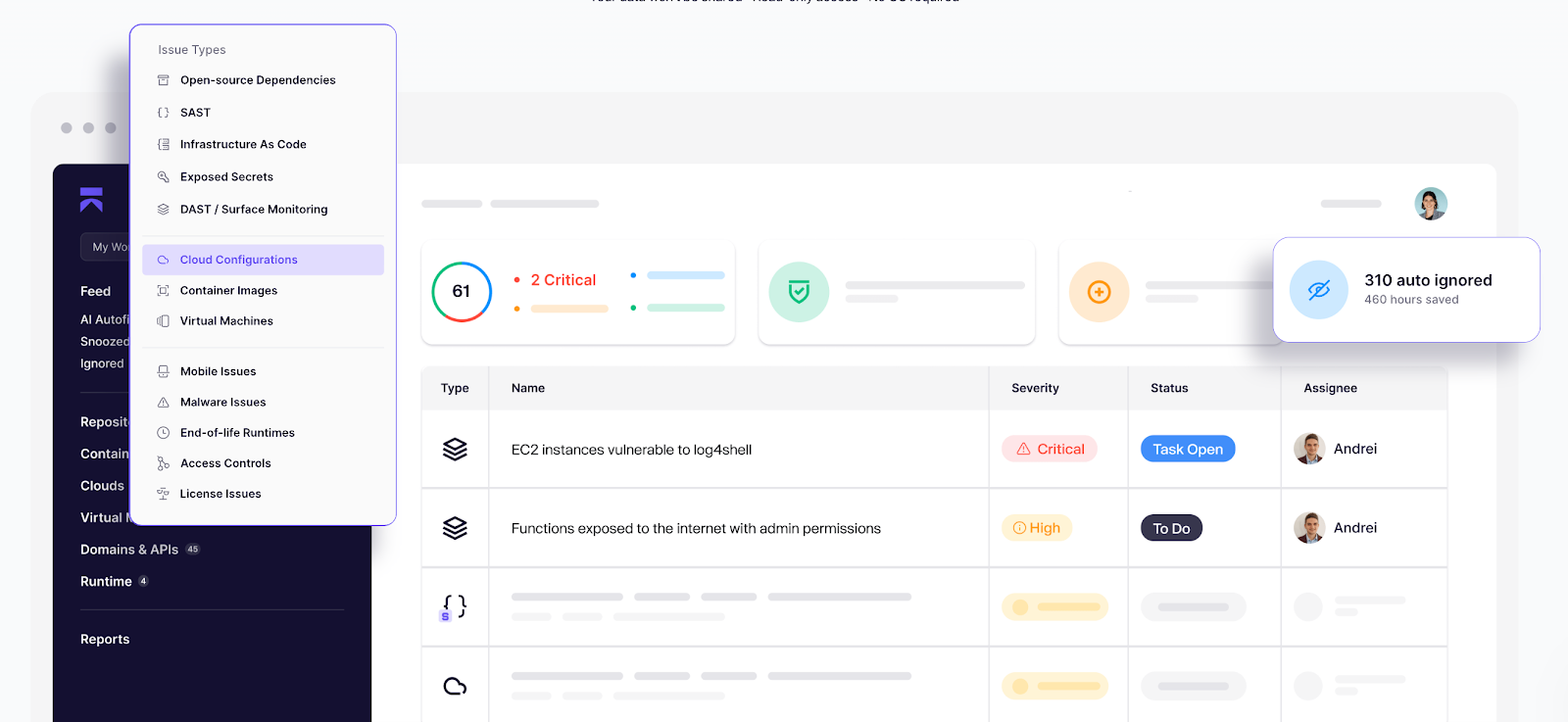
16. Software-Updates und Sicherheitspatches regelmäßig anwenden
Seien wir ehrlich: ungepatcht = anfällig.
Die allgemeine Empfehlung lautet, sicherzustellen, dass jede Ressource in Ihrer Infrastruktur auf eine stabile Version aktualisiert und gepatcht wird.
Aber wie lässt sich das in großem Maßstab mit Hunderten von Services und Tools umsetzen?
Hier glänzt KI mit Human-in-the-Loop, um Transparenz in Ihrer Infrastruktur zu schaffen und Probleme automatisch zu beheben.
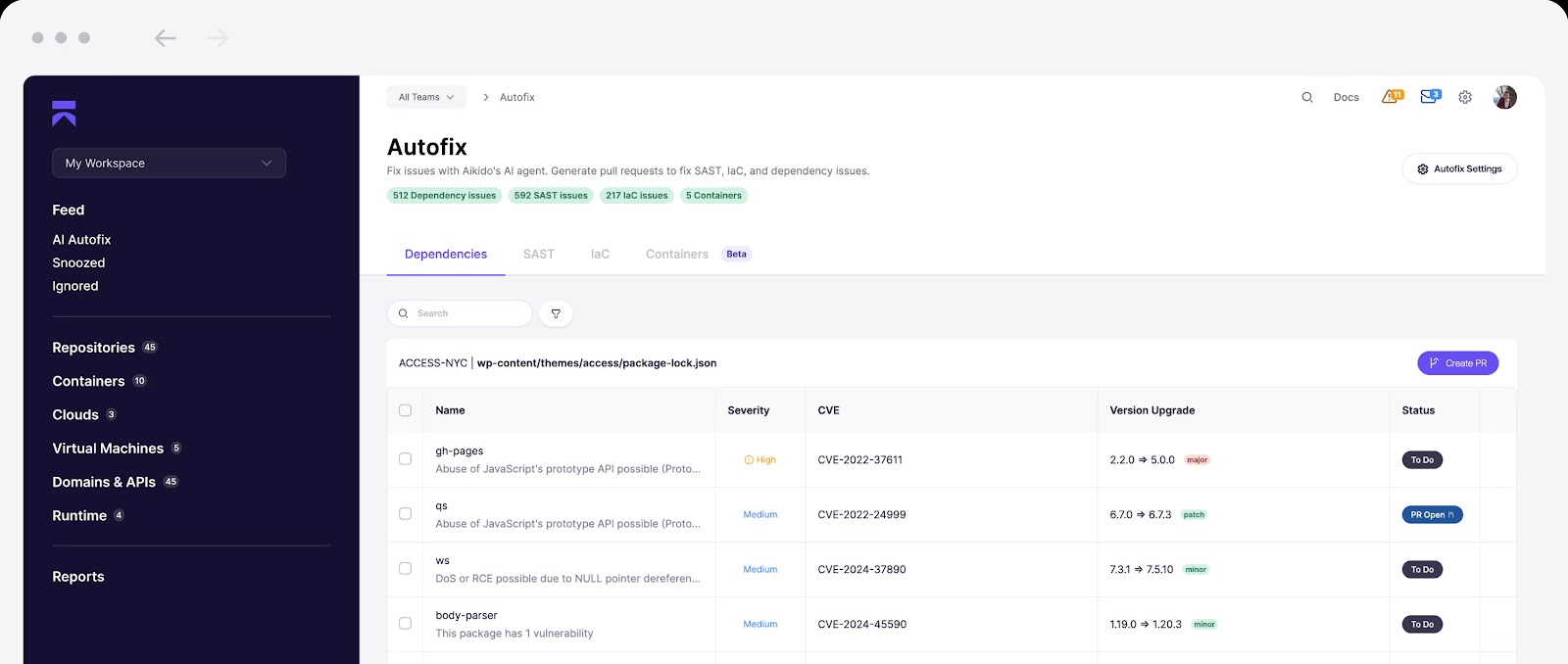
Best Practices zur Umsetzung:
- Generieren und verfolgen Sie SBOMs mit Tools, die automatisch Tickets für Probleme erstellen können, die Ihr Eingreifen erfordern.
- Abonnieren Sie CVE-Feeds, die von Sicherheitsforschern verifiziert werden, um über die neuesten Supply-Chain-Bedrohungen auf dem Laufenden zu bleiben.
- Bilder wöchentlich aus gepatchten Basis-Images neu erstellen; Digests pinnen, nicht Tags.
- Wartungsfenster + Canary Rollouts nutzen; Fehlerraten messen und schnell zurückrollen.
- Managed Services auf unterstützten Engine-Versionen halten (DBs, Runtimes, Gateways).
17. Anwendungs-Firewalls (WAFs) und DDoS-Schutz verwenden
WAFs filtern unerwünschten Traffic, und DDoS-Schilde halten Sie online, wenn der Traffic feindselig wird. Platzieren Sie sie vor APIs/Apps, um SQLi/XSS zu blockieren und L7-Floods zu drosseln, und kombinieren Sie sie dann mit Ratenbegrenzungen und Bot-Kontrollen für den Grauzonen-Missbrauch, der Signaturen umgeht.
Wenn Sie sich an die obige Abbildung der Netzwerksegmentierung erinnern, befindet sich eine WAF zwischen dem Frontend-Load Balancer und dem Webserver.
Best Practices zur Umsetzung:
- Eine WAF (Aikido Zen/AWS WAF/Azure WAF/Cloud Armor) mit einem angepassten Regelsatz (OWASP CRS + custom) bereitstellen.
- DDoS-Schutz mit automatischer Mitigation aktivieren.
- JSON-Bodies (API-Modus) inspizieren, Schemas validieren und alle Blöcke in Ihr SIEM protokollieren.
- Chaos-Drills durchführen, um Spitzen zu simulieren und zu bestätigen, dass Autoscaling- und WAF/DDoS-Richtlinien wirksam sind.
Cloud-Sicherheit Bedrohungserkennung & Monitoring Best Practices
Das schnelle Erkennen und Reagieren auf Bedrohungen ist entscheidend, um die Auswirkungen von Sicherheitsvorfällen in der Cloud zu reduzieren, wodurch proaktive Monitoring- und Erkennungs-Best Practices zu einem kritischen Bestandteil der Cloud-Sicherheit werden.
18. Implementierung fortschrittlicher Monitoring- und Logging-Tools
Logs sind Ihr Frühwarnsystem. Allerdings nur, wenn Sie diese auch zentralisieren und analysieren.
In der Cloud verteilen sich Ereignisse über verschiedene Services: API calls, VM activity, Kubernetes audit logs, network flow data.
Führen Sie sie in einem SIEM oder Data Lake zusammen, erstellen Sie dann Dashboards mit Open-Source-Visualisierungstools wie Grafana und richten Sie Alarme ein, damit nichts übersehen wird.
Best Practices zur Umsetzung:
- Aktivieren Sie Cloud-native Protokollierung mit Services wie AWS CloudTrail, GuardDuty, VPC Flow Logs, Azure Monitor und GCP Cloud Audit Logs.
- Streamen Sie Logs an einen zentralen Ort zur Korrelation. Sie können und sollten einen Data Collector verwenden, um eine vereinheitlichte Logging-Schicht aufzubauen. Einer der robustesten ist Fluentd, der Open Source ist und über mehr als 500 Plugins zum Verbinden von Datenquellen undausgaben verfügt, während sein Kern einfach bleibt.
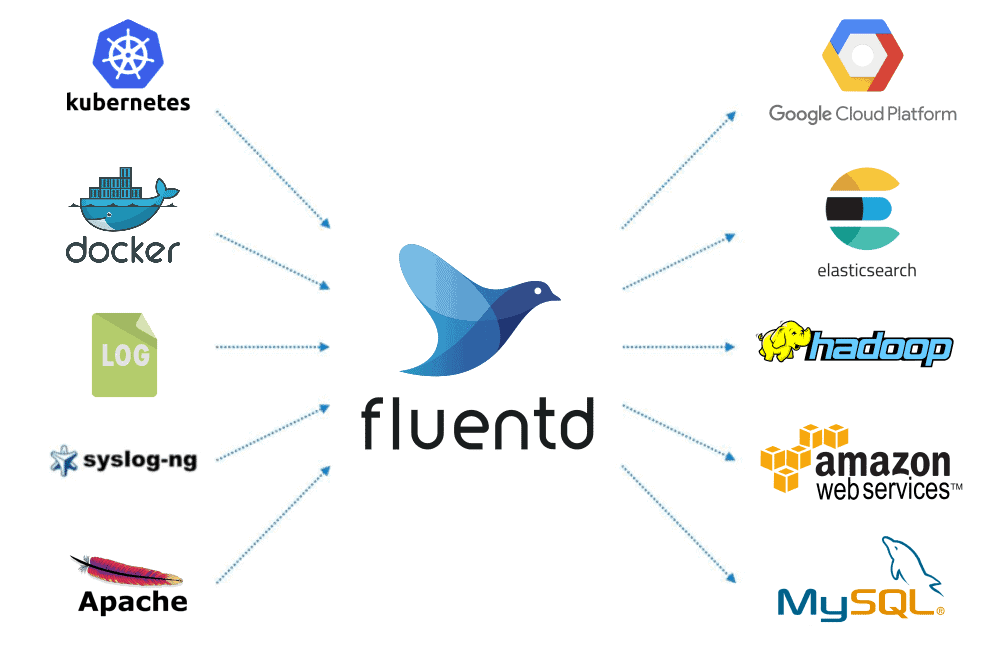
- Danach definieren Sie Alarme für risikoreiche Aktionen (IAM changes, new public buckets, privilege escalations).
- Legen Sie Richtlinien zur Log-Aufbewahrung fest, die Compliance- und forensischen Anforderungen erfüllen.
19. Verwenden Sie einen Abhängigkeitsgraphen für Schwachstellenbewertungen
Seit Beginn des Leitfadens haben wir die automatische Erkennung von Schwachstellen erwähnt. Es ist auch wichtig zu wissen, dass nicht alle Schwachstellen es wert sind, behoben zu werden. Wichtig ist zu wissen, welche davon tatsächlich ein Risiko in Ihrer bereitgestellten Umgebung darstellen.
Hier wird ein Abhängigkeitsgraph unerlässlich. Ohne ihn sind Sie blind, ertrinken in irrelevanten CVEs und übersehen gleichzeitig die wichtigen.
Best Practices zur Umsetzung:
- Nutzen Sie eine Plattform, die Erreichbarkeitsanalyse bietet, um Fehlalarme zu eliminieren und nur ausnutzbare Schwachstellen zu kennzeichnen.
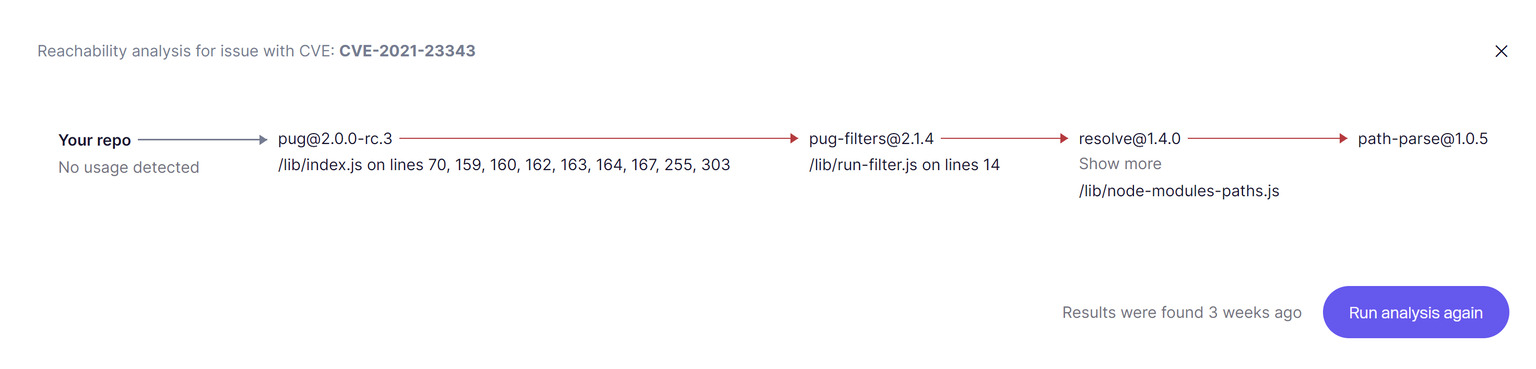
- Ignorieren Sie dev/test-spezifische Abhängigkeiten; konzentrieren Sie sich auf das, was in die Produktion geht.
- Priorisieren Sie CVEs, die sowohl erreichbar als auch dem Internet ausgesetzt sind.
- Korrelieren Sie Schwachstellen über Code, Container und Cloud-Konfigurationen hinweg.
20. Vorsicht vor Vibe Coding
Vibe Coding ist das glänzende neue Ding.
Designer, Marketer, Vertriebsmitarbeitende oder jeder kann jetzt Apps oder Features erstellen, ohne selbst viel Code zu schreiben. Dies bedeutet oft ohne Tests, Reviews oder Berücksichtigung der Sicherheit. Es ist schnell, reibungslos und fühlt sich magisch an. Aber Magie ohne Leitplanken neigt dazu, zu verbrennen.
Um sicherer zu „vibe coden“, sind die besten Praktiken, die zu übernehmen sind:
- Behandeln Sie KI-generierten oder nicht von Ingenieuren ausgelieferten Code, als hätte ihn ein Junior-Entwickelnde geschrieben: immer Code Review. Lassen Sie es von anderen prüfen.
- Entwickeln Sie keine eigene Authentifizierung, Eingabevalidierung oder Secrets-Management; verwenden Sie gut geprüfte, auditierte Bibliotheken oder Dienste.
- Halten Sie Secrets von Frontend und Repos fern; verwenden Sie sicheren Speicher und Umgebungsmanagement.
- Stellen Sie sicher, dass Sie Scans (Dependency, SAST, DAST) für vibe-coded Apps automatisieren, bevor Sie diese deployen. Lassen Sie Pipelines die offensichtlichen Schwachstellen erkennen.
Sie möchten weitere praktische Schritte? Lesen Sie unsere Vibe Coders’ Security Checklist.
21. Kontinuierliches Penetrationstesten in CI/CD
Kontinuierliches Penetrationstesten stellt periodische Sicherheitsüberprüfungen auf den Kopf, indem es automatisierte Tests in Ihre Build- und Deployment-Pipeline einbettet, sodass Schwachstellen bevor sie die Produktion erreichen, erkannt werden. Es geht um Geschwindigkeit, Kontext und sauberere Feedback-Schleifen.
Best Practices zur Umsetzung:
- Richten Sie SAST und Secrets-Scan bei jedem Pull Request ein.
- IaC-Scans in Ihrer CI (scannen Sie Terraform-Skripte, CloudFormation und Helm) vor dem Deployment.
- Lassen Sie Builds bei Schwachstellen mit hoher/kritischer Schwere fehlschlagen; kennzeichnen Sie mittlere Ergebnisse im Dashboard für das Backlog.
- Benennen Sie ein Team oder einen individuellen „Owner“ für jede Ergebnisklasse (Code, Infrastruktur, Cloud) mit dokumentierten SLAs.
- Führen Sie regelmäßige „Pentest-Retrospektiven“ durch, um Ergebnisse und False Positives zu überprüfen und die Tools zu optimieren.
Best Practices für Cloud-Sicherheit, Betrieb und Resilienz
Cloud-Sicherheit ist nicht nur Prävention; sie erfordert auch die Vorbereitung auf Störungen und die Sicherstellung der Geschäftskontinuität, weshalb Praktiken für operative Exzellenz und Resilienz entscheidend sind.
22. Etablierung von Incident Response Plänen
Sie kennen den Klischee-Spruch „Wer nicht plant, plant zu scheitern“; nun, dasselbe gilt in der Welt der Sicherheit.
Es geht nicht darum, ob Vorfälle auftreten werden, denn das werden sie; es geht darum, wie Sie reagieren, wenn sie passieren, und was Sie danach tun.
Was macht einen soliden Incident-Response-Plan aus?
- Sie müssen klare Linien ziehen, was als Vorfall zählt (Datenpanne, Dienstausfall durch Malware usw.). Ohne dies herrscht immer Verwirrung.
- Benennen Sie, wer was tut, seien es Entwickelnde, Tech Leads, Kommunikation oder Recht. Fügen Sie auch Backup-Kontakte hinzu.
- Intern und extern. Wer muss es wissen? Wann? Und wie?
- Legen Sie einen Schritt-für-Schritt-Ablauf fest: Erkennung → Bewertung → Eindämmung → Beseitigung → Wiederherstellung → Lehren gezogen. Fügen Sie Kriterien hinzu, wie schwerwiegend ein Vorfall sein muss, bevor er eskaliert wird (Schweregrade).
- Wenn Protokolle aufbewahrt, Systeme unter Quarantäne gestellt oder externe Hilfe benötigt werden, sollte der Plan die Beweissicherung umfassen.
- Führen Sie mindestens jährlich Tabletop- oder Simulationsübungen durch, um den Plan zu überprüfen und Lücken zu identifizieren.
23. Ein Zero-Trust-Sicherheitsmodell durchsetzen
Bisher haben wir Zero-Trust in diesem Leitfaden mehrfach erwähnt. Zero-Trust ist kein Produkt, das man kauft; es ist eine Denkweise: niemals vertrauen, immer verifizieren. In der Cloud, wo Netzwerke flach sind und Identitäten der neue Perimeter sind, ist dieses Modell wichtiger denn je.
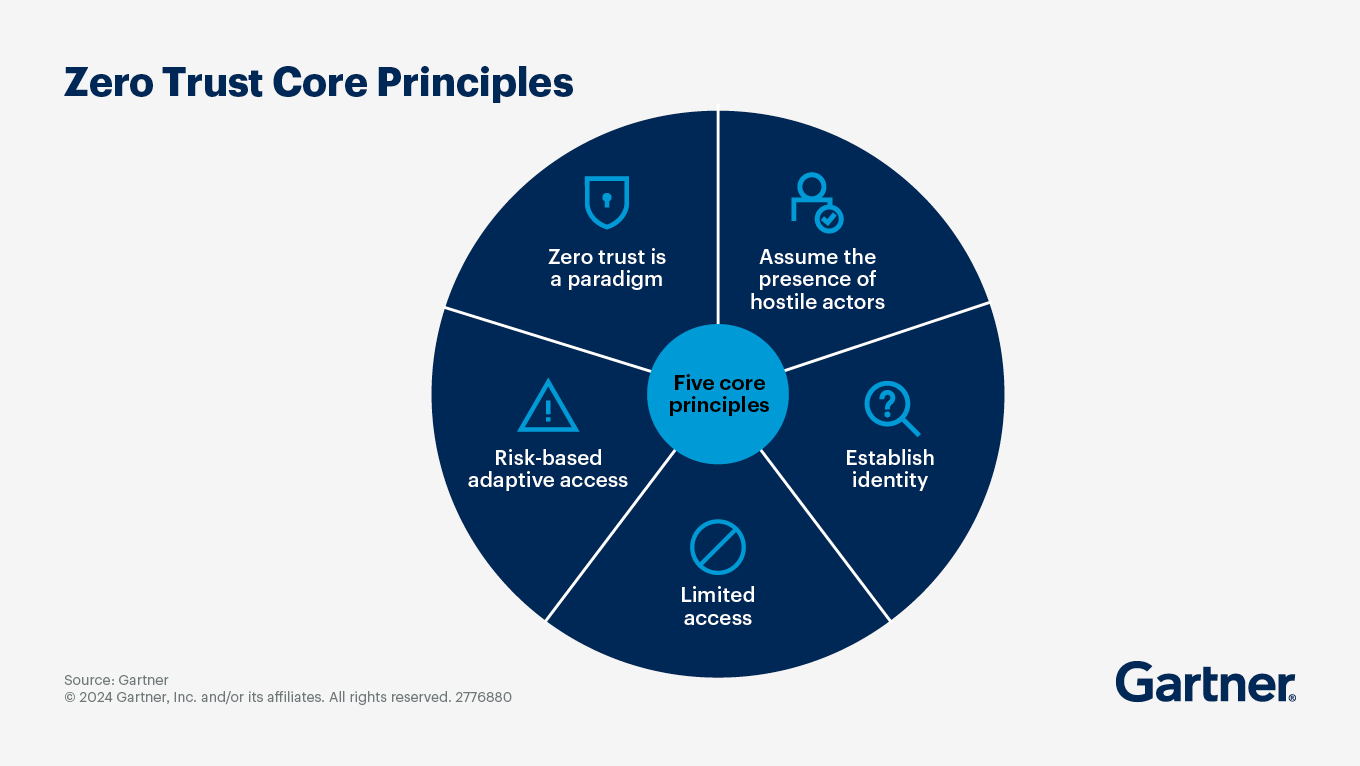
Anstatt davon auszugehen, dass Benutzer oder Dienste in Ihrer Umgebung sicher sind, zwingt Zero-Trust jede Anfrage, ob von Mensch oder Maschine, sich zu beweisen. Das bedeutet starke Authentifizierung, Least-Privilege-Autorisierung, verschlüsselte Verbindungen und kontinuierliche Validierung. Wenn ein Angreifer eindringt, hindert Zero-Trust ihn daran, sich lateral zu bewegen.
Best Practices zur Einführung:
- MFA und starke Identitätsprüfungen für jeden Benutzer und jede Workload erfordern.
- Das Prinzip der geringsten Rechte (Least Privilege) mit granularen RBAC-/ABAC-Richtlinien durchsetzen.
- Netzwerk-Mikrosegmentierung und Service-Identität, wie SPIFFE/SPIRE, nutzen, um den Machine-to-Machine-Traffic zu verifizieren.
- Den gesamten Traffic mit TLS/mTLS verschlüsseln, selbst innerhalb „vertrauter“ VPCs oder Cluster.
- Verhalten kontinuierlich überwachen und Sitzungen widerrufen, wenn Anomalien auftreten.
24. Cloud Access Security Broker (CASBs) nutzen
Die durchschnittliche Organisation nutzt eine Vielzahl von SaaS-Anwendungen, meist aus gutem Grund. Wenn man schnell vorankommen möchte, will man keine wertvollen Engineering-Stunden damit verbringen, das Rad neu zu erfinden. Die Herausforderung besteht darin, dass viele dieser Anwendungen ohne Sicherheitsaufsicht (Shadow IT) eingeführt werden, was blinde Flecken schafft.
Ein Cloud Access Security Broker (CASB) bietet einen zentralen Kontrollpunkt: Transparenz darüber, welche Anwendungen genutzt werden, welche Daten durch sie fließen und ob die Nutzung den Richtlinien entspricht.
CASBs setzen Kontrollen in SaaS-Umgebungen durch. Zu den Maßnahmen gehören das Verhindern des Hochladens sensibler Daten auf persönliche Laufwerke, die Forderung nach Verschlüsselung für die Dateifreigabe und das Blockieren von Anmeldungen von riskanten Standorten. Sie fungieren als Sicherheits-„Kleber“ zwischen Ihren Benutzern, SaaS-Anwendungen und bestehenden IAM- und DLP-Richtlinien.
Best Practices zur Umsetzung:
- Setzen Sie einen CASB im Proxy- oder API-Modus ein, um die SaaS-Nutzung in Ihrer Organisation zu überwachen.
- Schatten-IT identifizieren, indem nicht autorisierte Anwendungen entdeckt und riskante blockiert werden.
- DLP-Richtlinien durchsetzen, die verhindern, dass sensible Daten autorisierte Anwendungen verlassen.
- Kontextsensitiven Zugriff (Gerätezustand, Geolocation, Risikobewertung) vor der Gewährung von SaaS-Zugriff anfordern.
- CASBs in Ihr SIEM/SOAR für die Erkennung von Vorfällen und automatisierte Reaktion integrieren.
25. Eine starke Kultur des Sicherheitsbewusstseins entwickeln
All diese Best Practices, die wir in diesem Artikel behandelt haben, sind nutzlos, wenn die Menschen, die sie implementieren und leben sollen, sie vernachlässigen. Das Sprichwort „Eine Kette ist nur so stark wie ihr schwächstes Glied“ gilt auch für die Individuen in Ihrer Organisation.
Auch wenn Sie Ihr Team nicht mit obligatorischen Seminaren langweilen möchten, die wertvolle Zeit in Anspruch nehmen, die für die Iteration Ihrer Ziele genutzt werden könnte, möchten Sie dennoch ein Gleichgewicht finden, indem Sie Ihre Sicherheitslage ständig bewerten und sicherstellen, dass Ihre Teams die Auswirkungen eines ausgeprägten Sicherheitsbewusstseins verstehen.
Best Practices zur Umsetzung:
- Laufende Schulungen, Phishing-Simulationen und die Belohnung von sicherem Verhalten.
- Sicherheit zu einem Teil von Code-Reviews machen; nicht nur nach Fehlern suchen, sondern auch nach fest codierten Secrets, überprivilegierten API-Aufrufen und offenen Endpunkten.
- Sicherheitsbewusstsein gamifizieren, indem Bestenlisten für diejenigen integriert werden, die die meisten Schwachstellen finden, und Belohnungen für das Melden von Sicherheitsproblemen vergeben werden.
- Postmortems ohne Schuldzuweisung für Sicherheitsvorfälle. Wenn Menschen für ehrliche Fehler entlassen werden, werden sie diese beim nächsten Mal nur besser verstecken.
- Threat Modeling Sessions bringen Entwickelnde dazu, bereits in der Designphase wie Angreifer zu denken, nicht erst nach der Auslieferung des Codes.
Shift Left, Vorsprung bewahren, mit Vertrauen ausliefern
All dies vorausgeschickt, ist es wichtig zu verstehen, dass Sicherheit eher eine Reise als ein Ziel ist. Vor wenigen Jahren, wenn Sie uns bei Aikido gesagt hätten, dass „vibe coding security“ in einem Satz vorkommen würde, hätten Sie einige irritierte Blicke geerntet. Wir passen uns jedoch an und ergreifen proaktive Schritte, um sicherzustellen, dass Sie nicht wegen einer Sicherheitsverletzung auf der Titelseite landen.
Das ist im Wesentlichen der Grund, warum wir Aikido entwickelt haben: um Ihnen zu helfen, Shift Left zu praktizieren, Fehlkonfigurationen frühzeitig zu erkennen und Ihre Entwickelnde schnell vorankommen zu lassen, ohne Abstriche bei der Sicherheit zu machen.
Ihre Frage könnte nun lauten: Wie fange ich also an?
Die Antwort ist: Das haben Sie bereits getan. Indem Sie diese Best Practices durchgelesen und Schritte in Richtung stärkerer Cloud-Sicherheit unternommen haben. Der nächste Schritt ist einfach: Buchen Sie eine Demo mit unserem Team und sehen Sie, wie Aikido Ihnen die schwere Arbeit abnehmen kann, damit Sie sich auf das Wesentliche konzentrieren können: mit Vertrauen auszuliefern!
Lesen Sie weitere Artikel aus unserer Serie über Cloud-Sicherheit:
Cloud-Sicherheit: Der vollständige Leitfaden
Cloud-Anwendungssicherheit: SaaS und Benutzerdefinierte Cloud-Anwendungen sichern
Cloud-Sicherheitstools & -Plattformen: Der Vergleich 2025


