Einleitung
Die Wahl des richtigen Code-Sicherheitstools kann über den Erfolg oder Misserfolg Ihrer Entwicklungs-Sicherheitsstrategie entscheiden. Snyk und Semgrep werden oft für ihren entwicklerzentrierten Ansatz verglichen, Schwachstellen frühzeitig zu finden. Beide helfen Teams, sichereren Code zu liefern, indem sie Sicherheitsprüfungen in die Entwicklung integrieren – aber jeder hat einen anderen Fokus. Dieser Vergleich untersucht, wie sie sich schlagen und warum die Wahl für technische Führungskräfte, die für die sichere Softwarebereitstellung verantwortlich sind, wichtig ist.
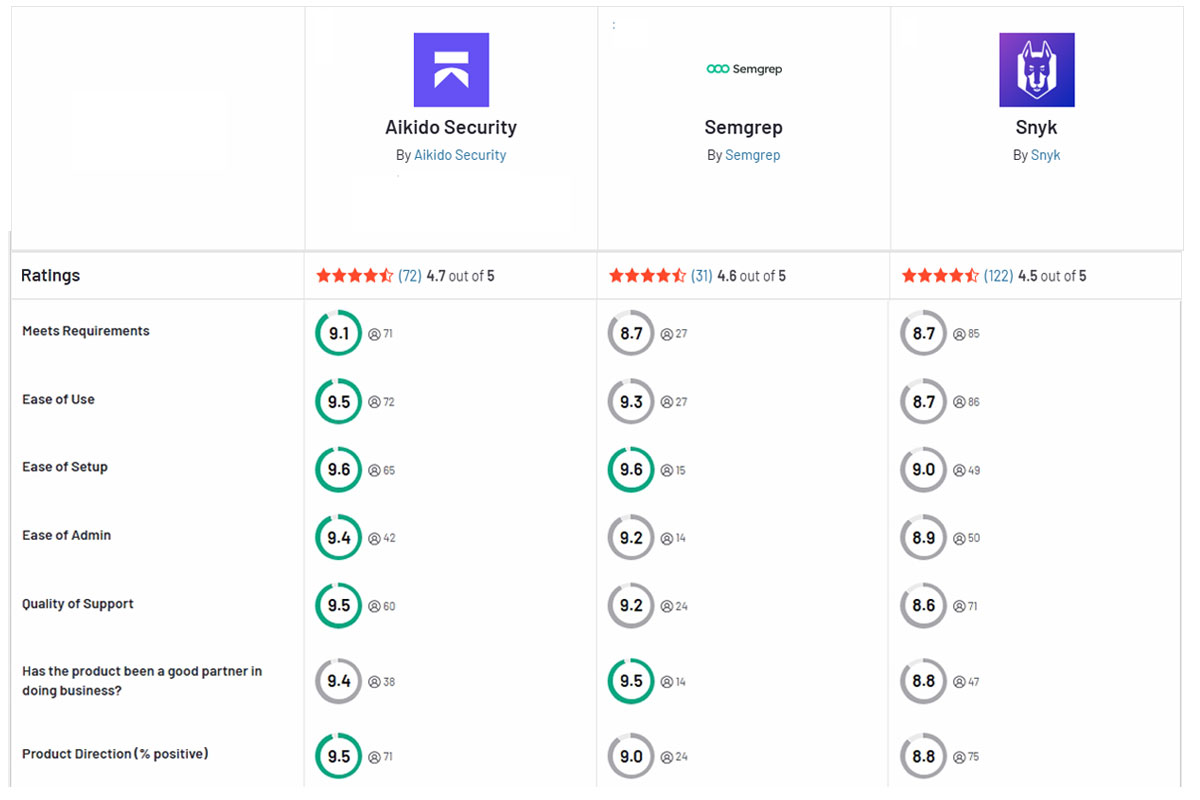
TL;DR
Snyk und Semgrep helfen beide, Ihre Codebasis zu sichern, aber sie konzentrieren sich auf verschiedene Ebenen – und beide haben blinde Flecken. Snyk ist hervorragend im Scannen von Open-Source-Abhängigkeiten und Containern, während Semgrep sich auf statische Codeanalyse spezialisiert hat. Aikido Security führt beide Welten auf einer Plattform zusammen, mit deutlich weniger Fehlalarmen und einfacherer Integration – was es zur besseren Wahl für moderne Sicherheitsteams macht.
Übersicht über Snyk und Semgrep
Snyk
Snyk ist eine entwicklerzentrierte Sicherheitsplattform, bekannt dafür, Schwachstellen in Open-Source-Bibliotheken und anderen Komponenten zu finden. Es begann mit Software-Kompositionsanalyse (SCA), um anfällige Abhängigkeiten zu erkennen, und erweiterte sich später auf das Scannen von Container-Images, Infrastructure-as-Code und sogar statischem Code über Snyk Code. Snyks Stärke liegt darin, sich nahtlos in Entwicklungsworkflows (wie GitHub, CI/CD-Pipelines und IDEs) zu integrieren, um Entwickelnde frühzeitig über Risiken zu informieren. Es betont „Shift-Left“-Sicherheit, was es bei agilen DevOps-Teams beliebt macht. Snyks breiter Ansatz bringt jedoch Kompromisse in Bezug auf Tiefe und Rauschen mit sich, die wir besprechen werden.
Semgrep
Semgrep ist ein Open-Source-Tool für statische Analyse (SAST), das sich auf das Scannen Ihres Quellcodes nach Fehlern und Sicherheitsproblemen konzentriert. Es verwendet flexible, regelbasierte Mustererkennung, um alles von Sicherheitslücken bis hin zu Fehlern in der Codequalität zu erfassen. Semgrep ist leichtgewichtig und sprachbewusst, wodurch es schnell in CI-Pipelines ohne aufwendige Einrichtung ausgeführt werden kann. Sein Hauptreiz ist die Anpassbarkeit: Teams können ihre eigenen Regeln in YAML schreiben, um spezifische Muster zu erkennen, was eine große Flexibilität bei der Anpassung der Scans an ihre Codebasis ermöglicht. Dieses entwicklerzentrierte Design hat Semgrep zu einem Favoriten für diejenigen gemacht, die eine praktische Kontrolle über das Code-Scanning wünschen. Der enge Fokus von Semgrep (nur Code) bedeutet jedoch, dass es standardmäßig keine Open-Source-Paket-Schwachstellen, Container oder Infrastrukturprobleme abdeckt, sodass es nur einen Teil des Sicherheitspuzzles löst.
Funktionsvergleich
Sicherheits-Scanning-Funktionen
Snyks Abdeckung: Snyk bietet eine breite Palette von Scanning-Funktionen unter einem Dach. Es ist am stärksten in SCA (Scan von Softwareabhängigkeiten) – hierbei wird eine Schwachstellendatenbank verwendet, um riskante Bibliotheken in Ihrer Anwendung zu kennzeichnen. Snyk scannt auch Container-Images und IaC (Infrastructure as Code)-Konfigurationen auf bekannte Probleme, um den gesamten Stack zu sichern. Zusätzlich bietet Snyk Code eine SAST-Analyse für Ihren Code, obwohl dies ein neuerer Bereich für Snyk und nicht dessen Kernkompetenz ist. In der Praxis ist Snyk am besten dafür bekannt, bekannte Schwachstellen (wie veraltete Bibliotheken mit einer CVE) zu erkennen und Entwickelnden zu helfen, diese frühzeitig zu beheben.
Semgreps Abdeckung: Semgrep konzentriert sich hingegen auf statische Codeanalyse. Es zeichnet sich dadurch aus, dass es Codierungsfehler, unsichere Muster und Logikfehler in Ihrem eigenen Code mithilfe Hunderter von der Community geschriebener Regeln (und der Möglichkeit, eigene Regeln zu schreiben) erkennt. Es verfügt nicht über eine integrierte CVE-Datenbank für Open-Source-Pakete oder scannt Container/IaC standardmäßig. (Semgrep hat separate Add-ons wie „Semgrep Supply Chain“ und „Semgrep Secrets“, aber das sind eigenständige Tools in seinem Ökosystem.) Der primäre Anwendungsfall ist das Auffinden von Problemen im Anwendungscode selbst – z. B. eine unsichere Verwendung von eval oder eine fehlende Eingabebereinigung – anstatt Schwachstellen in Drittanbieterkomponenten. Dies bedeutet, dass Semgrep Sicherheitslücken aufdecken kann, die Snyks Abhängigkeitsscanner möglicherweise übersieht, aber Semgrep wird alles außerhalb des Codes übersehen (wie eine anfällige Bibliotheksversion oder ein falsch konfiguriertes Docker-Image).
Hauptunterschied: Snyk verfolgt einen breiteren, komponentenzentrierten Ansatz (Code, Abhängigkeiten, Container, Konfiguration), während Semgrep einen tieferen, codezentrierten Ansatz verfolgt. Wenn Sie ein Tool benötigen, um Ihre Open-Source-Pakete auf bekannte Schwachstellen zu scannen, ist Snyk die richtige Wahl. Wenn Sie sich mehr Sorgen um den Benutzerdefinierten Code machen, den Ihr Team schreibt, ist Semgreps statische Analyse direkter. Beide Tools weisen Lücken auf – Snyks statische Codeanalyse ist nicht so gründlich wie die von Semgrep, und Semgrep bietet allein keine Abdeckung für Supply-Chain-Schwachstellen. Technische Führungskräfte verwenden oft mehrere Tools oder eine kombinierte Plattform (wie Aikido), um beide Bereiche abzudecken.
Integration & DevOps-Workflow
Snyk-Integration: Eines der größten Verkaufsargumente von Snyk ist, wie gut es sich in die bestehenden Workflows von Entwickelnden einfügt. Es bietet Plugins für gängige IDEs (damit Entwickelnde sofortige Warnungen beim Codieren erhalten), native Integrationen mit GitHub/GitLab/Bitbucket und CI/CD-Pipeline-Hooks, die Builds bei Sicherheitsproblemen fehlschlagen lassen können. Snyks Cloud-Dienst überwacht Ihre Repositorys; wann immer Sie einen Pull Request öffnen oder neuen Code pushen, kann Snyk Probleme in der Git-Anbieter-Benutzeroberfläche scannen und melden. Entwickelnde schätzen, dass Snyk die Ergebnisse direkt dort anzeigt, wo sie arbeiten – ein Nachteil ist jedoch, dass Snyk Benutzer oft in sein Web-Dashboard für Details leitet, was zu Kontextwechseln führt.
Bemerkenswert ist, dass Snyk eine verwaltete SaaS-Plattform ist, was bedeutet, dass Ihr Code (oder Abhängigkeitsmanifest) zur Analyse in deren Cloud hochgeladen wird. Dies erleichtert die Einrichtung (keine Serverwartung), aber einige Unternehmen zögern, Quellcode nach außen zu senden, und Snyks Fehlen von on-premise-Optionen kann in stark regulierten Umgebungen ein Hindernis sein. Außerdem unterstützt Snyk hauptsächlich Cloud-Repos (bei Verwendung der Snyk SCM-Integration) – Änderungen wie die Umbenennung eines Repos können sogar die Verbindung unterbrechen. Insgesamt ist die Integration von Snyk unkompliziert, wenn Sie bereits Cloud-basiert sind und gängige Entwickler-Tools verwenden. Es ist eine „Plug-and-Play“-Lösung für Teams, die DevSecOps praktizieren, mit dem Vorbehalt, dass Sie innerhalb des Snyk-Ökosystems arbeiten werden.
Semgrep-Integration: Semgreps Ansatz ist flexibler und entwicklergesteuerter. Da es Open-Source ist, können Sie die Semgrep CLI lokal oder in CI mit minimalem Aufwand ausführen – Sie müssen sich nicht für einen Dienst anmelden, wenn Sie dies nicht möchten. Das bedeutet, Sie können Semgrep-Scans überall integrieren: einen Pre-Commit-Hook, einen GitHub Actions Workflow, eine Jenkins-Pipeline, was auch immer. Viele Teams verwenden die offizielle Semgrep GitHub Action oder die CI/CD-Integrationen, um Semgrep-Checks bei jedem Pull Request hinzuzufügen, die dann Kommentare direkt in der Codeüberprüfung hinterlassen. Dieses In-Line-Feedback (Probleme als Kommentare in Ihrem PR sehen) erleichtert es Entwickelnden, Code-Probleme zu beheben, ohne den Kontext zu einer anderen Anwendung wechseln zu müssen.
Semgrep verfügt auch über eine optionale SaaS-Plattform (Semgrep App), die Ergebnisse aggregiert, eine Benutzeroberfläche und Funktionen für die Teamzusammenarbeit bietet – ähnlich der Snyk-Oberfläche, aber optional. Wichtig ist, dass Sie Semgrep bei Bedarf vollständig offline ausführen können, was für Teams mit strengen Anforderungen an die Code-Privatsphäre attraktiv ist. Die Lernkurve zur Integration von Semgrep ist für die grundlegende Nutzung gering (die CLI ist unkompliziert), aber die Optimierung für Ihre Umgebung kann das Schreiben oder Auswählen der richtigen Regeln erfordern, was ein zusätzlicher Schritt ist, den wir unter „Genauigkeit“ behandeln werden. In Bezug auf Plattformabhängigkeiten ist Semgrep Tool-agnostisch: Es ist egal, welches Git-System oder welche CI Sie verwenden, und es erzwingt kein bestimmtes Repo-Hosting (im Gegensatz zu beispielsweise GitHub-only-Lösungen).
Diese Flexibilität macht Semgrep passend für vielfältige Workflows, wenn auch mit mehr manueller Abstimmung im Vergleich zu Snyks „Click-and-Go“-Integrationen.
Genauigkeit und Leistung
Fehlalarme & Rauschen: Genauigkeit ist ein entscheidender Faktor für jedes Sicherheitstool – zu viele Fehlalarme, und Entwickelnde beginnen, das Tool zu ignorieren. Hier haben sowohl Snyk als auch Semgrep Kritik erfahren, jedoch auf unterschiedliche Weise. Snyks SAST (Code)-Scanning hat den Ruf, hohe Fehlalarmraten in bestimmten Sprachen zu haben. Entwickelnde berichten oft, dass sie mit Befunden überflutet werden, die keine tatsächlichen Schwachstellen sind, was das Vertrauen in das Tool untergraben kann. Ein Grund dafür ist, dass Snyks Regeln meist verallgemeinert und proprietär sind, was den Benutzern nur begrenzte Sichtbarkeit oder Kontrolle zur Anpassung gibt.
Wenn Snyk etwas kennzeichnet, können Sie es ignorieren oder patchen – aber Sie können die Regellogik nicht einfach anpassen. Dieser „Black-Box“-Ansatz frustriert Sicherheitsteams manchmal, wenn sie wissen, dass ein Befund kein Problem ist, ihn aber immer wieder als markiert sehen. Semgrep hingegen kann auch standardmäßig verrauschte Ergebnisse liefern. Da es auf Musterregeln basiert, kann ein nicht abgestimmter Semgrep-Lauf viele potenzielle Probleme kennzeichnen, einschließlich kleinerer Stilprobleme oder Fehlalarme, je nachdem, welche Regelsätze Sie verwenden. Tatsächlich erfordert der effektive Einsatz von Semgrep oft die Kuration Ihrer Regeln, um das Rauschen zu reduzieren – Sie könnten mit einem breiten Regelsatz beginnen und dann Regeln deaktivieren, die nicht relevant oder zu verrauscht sind.
Der Vorteil ist, dass Sie diese Kontrolle haben: Semgrep bietet Sichtbarkeit auf Regelebene und die Möglichkeit, spezifische Regeln zu ändern oder zu unterdrücken, sodass Teams im Laufe der Zeit Fehlalarme erheblich reduzieren können. Im Gegensatz dazu erlaubt Snyk keine Anpassung seiner integrierten Regeln, was im Vergleich wie ein stumpfes Instrument wirken kann.
Fehlende Erkennungen & blinde Flecken: Genauigkeit bezieht sich nicht nur auf Fehlalarme; es geht auch darum, was jedes Tool nicht erfasst. Da Snyk bei vielen seiner Befunde auf bekannte Schwachstellendaten angewiesen ist, könnte es Probleme im Benutzerdefinierten Code übersehen, die keine CVE oder bekannte Signatur haben. Snyk Code (sein SAST) versucht, diese zu finden, aber wie bereits erwähnt, ist es ein neuerer Akteur und könnte komplexe logische Fehler, die Semgrep mit einer gut geschriebenen Regel erfassen könnte, möglicherweise nicht erkennen.
Umgekehrt erkennt Semgrep möglicherweise nicht, dass eine bestimmte Abhängigkeit anfällig ist (es sei denn, Sie haben eine Regel geschrieben, um eine spezifische Versionszeichenfolge oder ein Nutzungsmuster zu erkennen), sodass es ein Problem wie „Diese Bibliothek aktualisieren, sie hat eine bekannte RCE-Schwachstelle“ vollständig übersehen könnte. Jedes Tool hat blinde Flecken: Snyk kann bestimmte Datenfluss- oder Qualitätsprobleme im Code übersehen, und Semgrep kann anfällige Bibliotheksversionen oder Konfigurationsprobleme konstruktionsbedingt übersehen.
Geschwindigkeit & Leistung: Beide Tools sind darauf ausgelegt, relativ schnell und CI-freundlich zu sein, aber ihre Leistungsprofile unterscheiden sich. Snyks Scans, insbesondere für Abhängigkeiten, sind in der Regel schnell (ein Snyk Open Source-Scan kann Sekunden dauern). Snyk Codes Analyse ist Cloud-basiert und kann auch für moderate Codebasen Ergebnisse in unter einer Minute liefern. Semgrep läuft lokal (oder in Ihrem CI-Container) und ist angesichts seiner Gründlichkeit ziemlich leichtgewichtig – eine Codebasis von ~50.000 Zeilen könnte in ein oder zwei Minuten gescannt werden. In Community-Tests war Semgrep etwas langsamer als Snyk Code für reines Code-Scanning (z. B. 90 Sekunden vs. 45 Sekunden bei einem mittelgroßen Repo), aber in den meisten Fällen immer noch schnell genug für CI.
Beide können inkrementell ausgeführt werden (nur geänderter Code wird gescannt), um das Feedback bei Pull Requests zu beschleunigen. Es ist erwähnenswert, dass Snyks Leistungsvorteil teilweise von Cloud-Ressourcen herrührt, die die Arbeit erledigen, während Semgreps Geschwindigkeit von einer schlanken Engine stammt, die keine tiefgehende interprozedurale Analyse wie schwerere Enterprise-SAST-Tools versucht. Keines der Tools beeinträchtigt die Build-Zeiten bei richtiger Konfiguration erheblich, und beide unterstützen die parallele Ausführung mit Tests. Wenn Ihr Team Echtzeit-Feedback schätzt, könnte Snyks IDE-Plugin sofortige Ergebnisse beim Tippen liefern, während Semgreps Modell typischerweise beim Speichern oder Committen ausgeführt wird (obwohl es auch IDE-Erweiterungen gibt, sind diese weniger bekannt).
Zusammenfassend lässt sich sagen, dass beide Tools schnell genug für den praktischen Einsatz sind, aber Sie sollten bereit sein, Zeit in die Optimierung von Semgrep zu investieren, um nicht in Fehlalarmen zu ertrinken, und sich bewusst sein, dass Snyk gelegentlich Dutzende von Problemen kennzeichnen kann, die Entwickelnde durchforsten müssen.
Abdeckung und Umfang
Sprachen und Frameworks: Snyk und Semgrep preisen beide die Unterstützung mehrerer Sprachen an, aber ihre Breite unterscheidet sich. Snyk unterstützt viele Sprachen für das Abhängigkeitsscanning (im Grunde jede Sprache mit einem Paketmanager, von JavaScripts npm über Pythons pip bis hin zu Javas Maven usw.). Sein SAST (Snyk Code) unterstützt derzeit wichtige Sprachen wie Java, JavaScript/TypeScript, Python, C#, Ruby, PHP und einige andere. Benutzer haben jedoch festgestellt, dass Snyks Regelabdeckung je nach Sprache variiert – einige Ökosystem-Unterstützungen sind noch in der Entwicklung.
Sie sollten überprüfen, ob Snyk die von Ihnen verwendeten Frameworks umfassend abdeckt (zum Beispiel könnte es gängige Muster in Spring oder Express handhaben, aber eine obskurere Sprache oder ein Framework könnte eine schwächere Abdeckung aufweisen). Semgrep unterstützt eine breite Palette von Sprachen für das Muster-Scanning – von den populären (JS/TS, Python, Java, C, Go, Ruby usw.) bis hin zu Nischensprachen wie Terraform-Konfigurationen und Kotlin. Da Semgreps Regeln von der Community getrieben werden, hängt die Sprachabdeckung oft von der Verfügbarkeit der Regeln ab. Der Vorteil ist, dass, wenn Semgrep eine neue Sprache nicht nativ unterstützt, das Team sie oft schnell hinzufügt (oder Sie könnten Benutzerdefinierte Muster mit begrenzter Syntax schreiben).
Für die meisten modernen Stacks unterstützen sowohl Snyk als auch Semgrep Ihre Sprache – aber Snyk erfasst möglicherweise nicht alle frameworkspezifischen Probleme, bis sich seine Regeln weiterentwickeln, und Semgrep erfordert möglicherweise, dass Sie Regeln für hochmoderne Frameworks finden/schreiben, da es musterbasiert ist.
Problemtypen: Hinsichtlich der abgedeckten Arten von Sicherheitsproblemen ist Snyk sehr breit aufgestellt für bekannte Schwachstellen – es deckt nicht nur Code-Fehler ab, sondern auch Konfigurationsprobleme (wie unsichere Docker-Basis-Images oder falsch konfigurierte AWS Terraform-Skripte) und Secrets-Leaks im Code. Es ist eine zentrale Anlaufstelle für viele Kategorien: SAST, SCA, Container-Scanning, IaC-Scan, sogar einige Lizenz-Compliance für Open Source. Diese Breite kann jedoch den Fokus verwässern – bei wirklich komplexen Code-Schwachstellenmustern hat Snyk Code möglicherweise keine Regel, während eine Benutzerdefinierte Semgrep-Regel diese erfassen könnte. Die Erkennungsfähigkeiten von Semgrep erstrecken sich auf alles, was Sie als Muster kodifizieren können.
Standardmäßig enthält es Regeln für die OWASP Top 10 Web-App-Risiken, fest codierte Anmeldeinformationen, unsichere Kryptografie-Nutzung und mehr. Aber bemerkenswerterweise kennt Semgrep von Haus aus keine CVE-Datenbanken oder Container-Benchmarks – jede Überprüfung dafür muss in einer Regel kodiert werden. In der Praxis hat die Semgrep-Community Regeln für einige bekannte anfällige Abhängigkeitsmuster erstellt (z. B. die Verwendung einer API, die in bestimmten Bibliotheksversionen anfällig ist), aber dies ist kein Ersatz für ein dediziertes SCA-Tool. Wenn eine technische Führungskraft eine Abdeckung über den gesamten SDLC (Software Development Lifecycle) – vom Code bis zur Cloud – benötigt, ist weder Snyk noch Semgrep allein ausreichend. Snyk übersieht dynamische/Laufzeit-Aspekte und einige tiefgreifende Code-Logiken, während Semgrep Umgebungs- und Abhängigkeitsrisiken übersieht.
Hier kommen kombinierte Plattformen oder mehrere Tools ins Spiel. Zum Beispiel deckt Aikido Security sowohl SAST als auch SCA in einem ab, um diese Lücken zu vermeiden und eine breitere Abdeckung zu bieten als Snyk oder Semgrep einzeln.
Bemerkenswerte Lücken: Um die Einschränkungen des Umfangs zusammenzufassen: Semgreps Fokus ist eng gefasst – es scannt Secrets, Cloud-Konfigurationen, Container usw. nicht ohne zusätzliche Hilfe. Snyks Fokus ist breit, aber oberflächlich in der Code-Analyse – es kann viele Abhängigkeits- und Konfigurationsprobleme kennzeichnen, aber einige Benutzerdefinierte Code-Schwachstellen übersehen oder oberflächliche Erkenntnisse liefern. Außerdem hat Snyk einige technische Einschränkungen: Zum Beispiel scannt es in der Code-Analyse keine sehr großen Dateien (>1 MB), sondern überspringt sie stillschweigend, was unentdeckte Risiken hinterlassen könnte, wenn Sie riesige automatisch generierte Code- oder Datendateien in Ihrem Repository haben. Semgrep hat typischerweise keine solchen Dateigrößenbeschränkungen, da Sie steuern, was gescannt werden soll. Im Wesentlichen deckt jedes Tool ab, was das andere auslässt: eines führt Open-Source- und Umgebungs-Scans durch, das andere Code-Muster-Scans. Eine Überlappung ihrer Abdeckung erfordert Integrationsaufwand oder die Verwendung einer Alternative, die diese Scans vereinheitlicht.
Entwickelnde Experience
Benutzerfreundlichkeit: Aus Sicht der Entwickelnden ist Snyk sehr benutzerfreundlich im Einstieg – man meldet sich an, verbindet ein Repo oder führt einen CLI-Befehl aus, und es liefert Ergebnisse mit Hinweisen zur Behebung. Die Benutzeroberfläche ist ausgefeilt, und die Ergebnisse verlinken oft zu zusätzlichen Informationen (wie CVE-Details oder Beispiellösungen), was praktisch sein kann. Die Entwickelnden erhalten geführte Korrekturen, insbesondere für Open-Source-Schwachstellen – Snyk kann sogar automatisch einen Pull Request öffnen, um eine Abhängigkeitsversion für Sie zu aktualisieren, was für vielbeschäftigte Teams eine nette Geste ist. Allerdings haben sich Entwickelnde beschwert, dass die Verwendung von Snyk zu einem „Vulnerability Whack-a-Mole“ werden kann: Man behebt ein Problem, und der nächste Scan zeigt weitere an, manchmal sogar erneut Probleme, die aufgrund fehlenden Kontexts eigentlich keine sind. Da Snyks detaillierte Informationen auf ihrer Plattform verfügbar sind, müssen Entwickelnde ihre Code-Umgebung verlassen, um sich im Snyk-Portal zur Triage von Problemen anzumelden. Dieser Kontextwechsel kann die Akzeptanz beeinträchtigen – es fühlt sich eher wie ein externer Prozess an als Teil des Codierens.
Semgreps Developer UX: Semgrep verfolgt einen stärker integrierten Ansatz für die Developer Experience. Wenn es so eingerichtet ist, dass es Pull Requests kommentiert, erhalten Entwickelnde Sicherheitsfeedback direkt in der Code-Überprüfung. Dies ist wesentlich unmittelbarer und hält den Behebungsworkflow parallel zum Entwicklungsworkflow. Entwickelnde können den Befund direkt im PR diskutieren, Code anpassen und einen Fix pushen – alles ohne ein separates Dashboard aufrufen zu müssen. Darüber hinaus sind Semgreps Befunde oft unkompliziert („Diese Zeile sieht nach einem SQL-Injection-Risiko aus, erwägen Sie die Verwendung parametrisierter Abfragen“), da die Regeln Benutzerdefinierte Nachrichten enthalten können.
Diese Klarheit und der In-Context-Ansatz führen dazu, dass Entwickelnde weniger defensiv sind; es fühlt sich eher wie Code-Review-Feedback an als wie ein externes Audit. Andererseits kann Semgrep von Entwickelnden verlangen, sich stärker an der Feinabstimmung von Regeln oder der Behandlung von False Positives zu beteiligen, als dies bei Snyk der Fall wäre. Die Lernkurve zum Schreiben einer Benutzerdefinierten Semgrep-Regel ist nicht steil (insbesondere für Ingenieure, die mit Codierung vertraut sind), aber es ist zusätzliche Arbeit. Einige Entwickelnde empfinden die Rohausgabe von Semgrep (wenn die PR-Integration nicht verwendet wird) auch als etwas „noisy“, bis sie konfiguriert ist. In Bezug auf die Benutzeroberfläche verbessert sich die Semgrep-App (falls Sie sie verwenden), ist aber nicht so ausgereift oder umfassend wie Snyks Oberfläche zur Verfolgung von Problemen über Projekte hinweg. Sie ist bewusst minimalistisch – passend zum pragmatischen Ansatz – aber für größere Teams sind Dinge wie Workflow-Tracking, Zuweisung und historische Metriken weniger ausgebaut.
Eine technische Führungskraft könnte feststellen, dass Snyk mehr „Enterprise“-Reporting (Dashboards, Compliance-Berichte usw.) bietet, während Semgrep darauf abzielt, Warnungen zeitnah an Entwickelnde zu liefern. Dies ist ein philosophischer Unterschied: Snyk versucht, eine One-Stop-Plattform zu sein (mit Dashboards für Manager), während Semgrep die Integration in den Entwicklungs-Workflow und Flexibilität gegenüber ausgefallenen Dashboards priorisiert.
Automatisierung & Korrekturen: Beide Tools entwickeln sich weiter, wie sie bei der Behebung von Problemen helfen. Snyk bietet automatisierte Fix-Pull-Requests für Abhängigkeitsprobleme und zeigt Beispiellösungen für Code-Probleme (oft nur ein Snippet aus ihrer Wissensdatenbank). Semgrep hat eingeführt Semgrep AutoFix/Assistent, der KI nutzt, um tatsächliche Code-Änderungen für bestimmte Befunde vorzuschlagen. Wenn Semgrep beispielsweise eine gefährliche Verwendung von eval, schlägt der Assistent möglicherweise ein sichereres Code-Snippet als Ersatz vor. Frühes Feedback deutet darauf hin, dass dies Entwickelnden Zeit sparen kann, auch wenn es nicht perfekt ist. Snyks Ansatz ist traditioneller – es ändert Ihren Code nicht automatisch (abgesehen von Abhängigkeiten), sondern gibt Anleitungen.
Je nach Präferenz Ihrer Entwickelnden bevorzugen sie möglicherweise Semgreps Versuch von Auto-Fixes, oder sie bevorzugen Snyks explizite Referenzen. Umgang mit False Positives: Noch ein Hinweis zur Developer Experience: Wenn ein Befund eigentlich kein Problem ist, wie leicht kann er abgewiesen werden? In Snyk können Sie Dinge als ignoriert markieren (mit Ablaufoptionen), aber wenn die Regel in leicht abweichendem Code ausgelöst wird, sehen Sie sie erneut.
Da Sie in Semgrep die Regel vollständig ändern oder deaktivieren können, haben Sie eine dauerhaftere Lösung (obwohl Sie vorsichtig sein müssen, nichts Reales zu deaktivieren). Entwickelnde, die es hassen, denselben Fehlalarm wiederholt zu sehen, könnten es schätzen, dass Semgrep aus Feedback lernt (wenn Sie ein Ergebnis als falsch markieren, können Sie die Regel anpassen, um dieses Muster nicht mehr zu kennzeichnen). Mit Snyk haben Entwickelnde manchmal das Gefühl, an die Eigenheiten des Tools gebunden zu sein und mit bestimmten unwesentlichen Problemen leben oder diese jedes Mal manuell herausfiltern zu müssen.
Preise und Wartung
Snyk-Preise: Snyk ist ein kommerzielles SaaS mit einem gestaffelten Preismodell. Es bietet einen kostenlosen Tarif für kleine oder Open-Source-Projekte (mit einigen Einschränkungen bei der Anzahl der Tests), aber eine ernsthafte Nutzung auf Team- oder Unternehmensebene erfordert einen kostenpflichtigen Plan. Snyk berechnet in der Regel pro Entwickelnden-Platz (und möglicherweise pro Projekt für bestimmte Produkte), was teuer werden kann, wenn das Entwicklungsteam wächst. Organisationen stellen oft fest, dass die Kosten stark steigen, wenn sie Snyk über Dutzende von Repositorys und Entwickelnden hinweg integrieren – was sie manchmal dazu veranlasst, nur kritische Repositorys selektiv zu scannen, um die Kosten zu kontrollieren. Der Enterprise-Plan von Snyk bietet zusätzliche Funktionen wie Benutzerdefiniertes SLA-Reporting und on-premise Support (in seltenen Fällen), die jedoch mit einem Aufpreis verbunden sind. Kurz gesagt, Snyk kann eines der teureren Tools in diesem Bereich sein, und die Budgetierung dafür ist eine Überlegung für eine Sicherheitsverantwortliche.
Semgrep-Preise: Der Kern von Semgrep ist Open Source und kostenlos nutzbar. Das bedeutet, Sie können unbegrenzte Scans über CLI oder CI durchführen, ohne einen Cent zu bezahlen, was ein großer Vorteil für budgetbewusste Teams ist. Das Unternehmen hinter Semgrep bietet jedoch kostenpflichtige Enterprise-Pläne (Semgrep Team/Enterprise) an, die eine verwaltete Cloud-Anwendung, zusätzliche Regelbibliotheken und Support umfassen. Diese Pläne werden typischerweise ebenfalls pro Platz (d.h. pro Entwickelnden- oder Projektplatz) berechnet. Dennoch, da Sie die Freiheit haben, die kostenlose Version zu nutzen, beginnen Teams oft mit der Semgrep Community Edition und ziehen eine Bezahlung nur in Betracht, wenn sie den Komfort der zentralisierten Plattform oder erweiterte Funktionen benötigen.
Die Wartung ist jedoch ein Kostenfaktor bei Semgrep – der Betriebsaufwand für die Verwaltung von Regeln und Tools. Anstelle eines Abonnements investieren Sie Ingenieurzeit, um die Regeln auf dem neuesten Stand zu halten und Ergebnisse zu triagieren. Für ein kleines Team mit wenigen Repositorys sind diese Kosten vernachlässigbar. Aber für eine größere Organisation kann die Pflege einer großen Anzahl Benutzerdefinierter Semgrep-Regeln und -Unterdrückungen zu einem erheblichen Aufwand werden. Einige Unternehmen mindern dies, indem sie die Community-Regelpakete nutzen und Beiträge zurückgeben, wodurch ein Teil der Wartung effektiv an die Community ausgelagert wird. Dennoch ist es wichtig zu berücksichtigen, dass Semgrep nicht „kostenlos“ ist, wenn man die Entwicklungszeit für die Optimierung im großen Maßstab mitzählt.
Wartung & Infrastruktur: Mit Snyk ist die Infrastrukturwartung minimal – es ist Cloud-SaaS, sodass Sie keine Server warten müssen (es sei denn, Sie entscheiden sich für eine on-premise Appliance für Snyk, was ungewöhnlich ist und zusätzliche Kosten verursachen kann). Sie müssen jedoch die Integration verwalten (sicherstellen, dass jedes Repository verknüpft ist, jede Pipeline den Snyk-Schritt enthält usw.) und die CLI aktualisiert halten, wenn Sie sie dort verwenden. Snyk kümmert sich um die Aktualisierung der Schwachstellendatenbanken und die Verbesserung der Regeln auf ihrer Seite (manchmal können diese Updates auch über Nacht neue Ergebnisse einführen). Semgrep erfordert bei Selbsthosting, dass Sie die CLI aktualisiert halten (was so einfach ist wie ein pip install oder Binär-Download in CI).
Wenn Sie die Semgrep-App verwenden, ist es SaaS und wird von ihnen gewartet, aber Sie können bei Bedarf immer noch eine interne Bereitstellung hosten (was einen Server und etwas Einrichtung erfordert). Im Allgemeinen betrifft die Wartung von Semgrep eher den Inhalt (Regeln) als das Tool selbst.
Preistransparenz: Es ist erwähnenswert, dass die Enterprise-Preise von Snyk und Semgrep etwas komplex sein können. Snyk verhandelt oft kundenspezifische Enterprise-Angebote, und die Preise von Semgrep für den kostenpflichtigen Tarif sind nicht öffentlich bekannt, sondern erfordern in der Regel eine Kontaktaufnahme für ein Angebot. Hier unterscheidet sich Aikido Security: Aikido bietet ein einfacheres, pauschales Preismodell, das Sie nicht dafür bestraft, mehr Projekte oder Entwickelnde hinzuzufügen. Es ist tendenziell berechenbarer und kostengünstiger bei Skalierung im Vergleich zu den Kosten pro Platz von Snyk oder den kostenpflichtigen Plänen von Semgrep.
Vor- und Nachteile jedes Tools

Snyk Vorteile:
- Breite Sicherheitsabdeckung: Scannt Code, Open-Source-Abhängigkeiten, Container, Konfigurationsdateien und mehr auf einer Plattform und bietet so ein breites Sicherheitsnetz.
- Entwickelnden-freundliche Integration: Einfach in Repositorys, CI/CD und IDEs zu integrieren für automatisiertes Scannen und schnelles Feedback in Entwicklungs-Workflows.
- Umsetzbare Korrekturen für Abhängigkeiten: Bietet klare Upgrade-Anleitungen und sogar automatische Pull-Requests zur Behebung anfälliger Bibliotheken, was die Behebung von SCA-Problemen vereinfacht.
- Intuitive UI: Übersichtliches Dashboard mit Schwachstellendetails, Priorisierungshinweisen und Links zu weiteren Informationen, was für Entwickelnde hilfreich ist, die lernen, Probleme zu beheben.
Snyk Nachteile:
- Hohe False Positives in SAST: Ihre statische Codeanalyse kennzeichnet oft viele nicht-relevante Probleme, was zu Alarmmüdigkeit bei Entwickelnden führt.
- Oberflächliche Codeanalyse: Stark in der Erkennung bekannter CVEs, aber schwächer beim Auffinden komplexer Fehler in Benutzerdefiniertem Code (keine fortgeschrittene Datenfluss- oder Laufzeitanalyse wie bei einigen SAST-Tools).
- Teuer bei Skalierung: Die Pro-Entwickelnde-Preisgestaltung kann für große Teams teuer werden, und erweiterte Funktionen sind hinter Enterprise-Plänen gesperrt.
- Begrenzte Anpassbarkeit: Closed-Source-Regeln ohne Möglichkeit, die Erkennungslogik anzupassen; Sie müssen auf Hersteller-Updates warten oder umständliche Ignorierungsmechanismen verwenden, wenn etwas fehlerhaft ist.
- Potenzielle Integrationsprobleme: Erfordert das Hochladen von Daten in einen Cloud-Dienst (was einige Organisationen nicht zulassen können), und die Plattform kann das Scannen großer Dateien oder bestimmter Dateien ohne klare Benachrichtigung überspringen.

Semgrep Vorteile:
- Leistungsstarke statische Analyse: Hervorragend beim Auffinden von Code-Schwachstellen und Anti-Patterns mit leichtgewichtigen Regeln, die viele Sprachen und Frameworks abdecken.
- Hochgradig anpassbar: Sicherheitsingenieure können Benutzerdefinierte Regeln in YAML schreiben, um Muster zu identifizieren, die für ihre Codebasis relevant sind. Diese Flexibilität ermöglicht es, Probleme zu finden, die für Ihre Anwendung einzigartig sind und die generische Tools übersehen würden.
- Schnell und leichtgewichtig: Läuft schnell in CI-Pipelines mit minimalen Auswirkungen auf die Build-Zeiten und erfordert keine schwere Infrastruktur oder Cloud-Ressourcen für den Betrieb.
- Entwickelnde-zentrierter Workflow: Integriert sich in Pull Requests und Entwickelnde-Tools und bietet sofortiges, kontextbezogenes Feedback, das Entwickelnde nützlich finden (fühlt sich eher wie ein Teil des Code-Reviews an als ein externer Scanner).
- Open Source und transparent: Die Scanning-Engine und viele Regelsätze sind offen, was Teams volle Transparenz darüber ermöglicht, welche Prüfungen durchgeführt werden, und die Möglichkeit, diese anzupassen oder zu erweitern. Keine Black Boxes.
Semgrep Nachteile:
- Enger Fokus: Deckt nur Code (SAST) ab. Es fehlt eine integrierte Scan-Funktion für Open-Source-Abhängigkeitsschwachstellen, Secrets, Container oder IaC, sodass es nur einen begrenzten Bereich des Sicherheitsspektrums abdeckt. Teams benötigen zusätzliche Tools für eine vollständige Abdeckung.
- Hohes Rauschen ohne Feinabstimmung: Vordefinierte Regelsätze können viele Ergebnisse liefern, einschließlich Fehlalarmen, die eine vorherige Feinabstimmung erfordern, um irrelevante Regeln herauszufiltern und das Rauschen zu reduzieren. Diese Feinabstimmung erfordert Sicherheitsexpertise und eine kontinuierliche Anpassung, während sich der Code weiterentwickelt.
- Wartungsaufwand: Die Verwaltung einer großen Bibliothek Benutzerdefinierter Regeln und deren Aktualisierung bei Änderungen der Codebasis und der Bedrohungslandschaft ist ein fortlaufender Aufwand. Im Unternehmensmaßstab kann dies ohne dedizierte AppSec-Ingenieure zu einer Belastung werden.
- Begrenzter Kontext & Priorisierung: Ergebnisse basieren auf Musterübereinstimmungen ohne breiteren Kontext (z. B. ob der anfällige Code tatsächlich erreichbar oder zur Laufzeit ausnutzbar ist). Dies kann zu einer langen Liste von Problemen führen, ohne Hinweise darauf, welche davon wirklich relevant sind, im Gegensatz zu Tools, die Risikokontext einbeziehen.
- Weniger Enterprise-Funktionen: Es fehlen einige der Governance-, Berichts- und Compliance-Funktionen, die größere Organisationen wünschen könnten (z. B. Audit-Logs, rollenbasierter Zugriff, vordefinierte Compliance-Prüfungen). Semgrep verbessert sich hier, aber sein Hauptaugenmerk liegt weiterhin darauf, Entwickelnde zu befähigen, anstatt Auditoren zufriedenzustellen.
Aikido Security: Die bessere Alternative
Moderne Sicherheitsteams benötigen oft die Stärken von Snyk und Semgrep, ohne die damit verbundenen Probleme. Aikido Security wurde als eine vereinheitlichte Lösung entwickelt, die Code-Scanning und Scan von Softwareabhängigkeiten in einer entwickelndenfreundlichen Plattform vereint. Es deckt SAST und SCA gemeinsam ab, sodass Sie nicht gezwungen sind, mehrere Tools zu jonglieren.
Durch die Zusammenführung mehrerer Scan-Typen an einem Ort kann Aikido Schwachstellen kontextualisieren und Fehlalarme herausfiltern – und das Rauschen um bis zu 95 % reduzieren. Weniger Fehlalarme bedeuten, dass Entwickelnde den Ergebnissen tatsächlich vertrauen. Die Integration ist nahtlos: Aikido integriert sich in Ihre Repos und Pipelines wie Snyk, liefert aber auch Ergebnisse inline wie Semgrep, wodurch Reibungsverluste minimiert werden. Wesentliche Vorteile ergeben sich aus intelligenter Automatisierung – zum Beispiel KI-gestützte Korrekturen und Priorisierung – was Ihrem Team Zeit spart.
Im Gegensatz zu traditionellen Anbietern hält Aikido die Dinge unkompliziert und transparent. Die Preisgestaltung ist pauschal und vorhersehbar, wodurch die hohen Pro-Platz-Kosten vermieden werden, die Snyk oder Semgrep im großen Maßstab teuer machen. Kurz gesagt, Aikido bringt beide Welten auf einer Plattform zusammen, mit deutlich weniger Rauschen und Komplexität, was es zu einer besseren Wahl für Teams macht, die effektive Sicherheit ohne die übliche Tool-Müdigkeit wünschen.
Starten Sie eine kostenlose Testversion oder fordern Sie eine Demo an, um die vollständige Lösung zu erkunden.


