Der Internationale KI-Sicherheitsbericht 2026 ist eine der bisher umfassendsten Übersichten über die Risiken, die von Allzweck-KI-Systemen ausgehen. Er wurde von über 100 unabhängigen Expertinnen und Experten aus mehr als 30 Ländern erstellt und zeigt, dass, obwohl KI-Systeme Leistungen erbringen, die noch vor wenigen Jahren wie Science-Fiction wirkten, die Risiken von Missbrauch, Fehlfunktionen sowie systematischen und grenzüberschreitenden Schäden klar sind.
Er liefert überzeugende Argumente für eine bessere Evaluierung, Transparenz und Schutzmaßnahmen. Eine direkte Frage bleibt jedoch unerforscht: Wie sieht „sicher“ aus, wenn KI autonom gegen reale Systeme agiert?
Eine Zusammenfassung der interessanten Erkenntnisse aus dem Internationalen KI-Sicherheitsbericht umfasst:
- Mindestens 700 Millionen Menschen nutzen wöchentlich KI-Systeme, wobei die Akzeptanzraten schneller sind als die des Personal Computers in seinen Anfangsjahren
- Mehrere KI-Unternehmen veröffentlichten ihre Modelle für 2025 mit zusätzlichen Sicherheitsmaßnahmen, nachdem Tests vor der Bereitstellung nicht ausschließen konnten, dass die Systeme Nicht-Experten bei der Entwicklung biologischer Waffen helfen könnten. (!!!) (Es ist unklar, ob die zusätzlichen Sicherheitsmaßnahmen dies vollständig verhindern würden)
- Sicherheitsteams haben dokumentiert, dass KI-Tools in tatsächlichen Cyberangriffen sowohl von unabhängigen Akteuren als auch von staatlich unterstützten Gruppen eingesetzt wurden.
Der Bericht erörtert ausführlich die Ansätze zur Bewältigung vieler mit KI verbundener Risiken – hier ist unsere Einschätzung:
Wo Aikido dem Bericht zustimmt (und wie er noch weiter gehen könnte)
1. Eine mehrschichtige Verteidigung ist entscheidend
Der Bericht skizziert einen Defense-in-Depth-Ansatz für die KI-Sicherheit und unterteilt ihn in drei Schichten: den Bau sichererer Modelle während des Trainings, das Hinzufügen von Kontrollen bei der Bereitstellung und die Überwachung von Systemen, nachdem sie live sind. Wir stimmen der Anwendung dieser Schichten weitgehend zu.
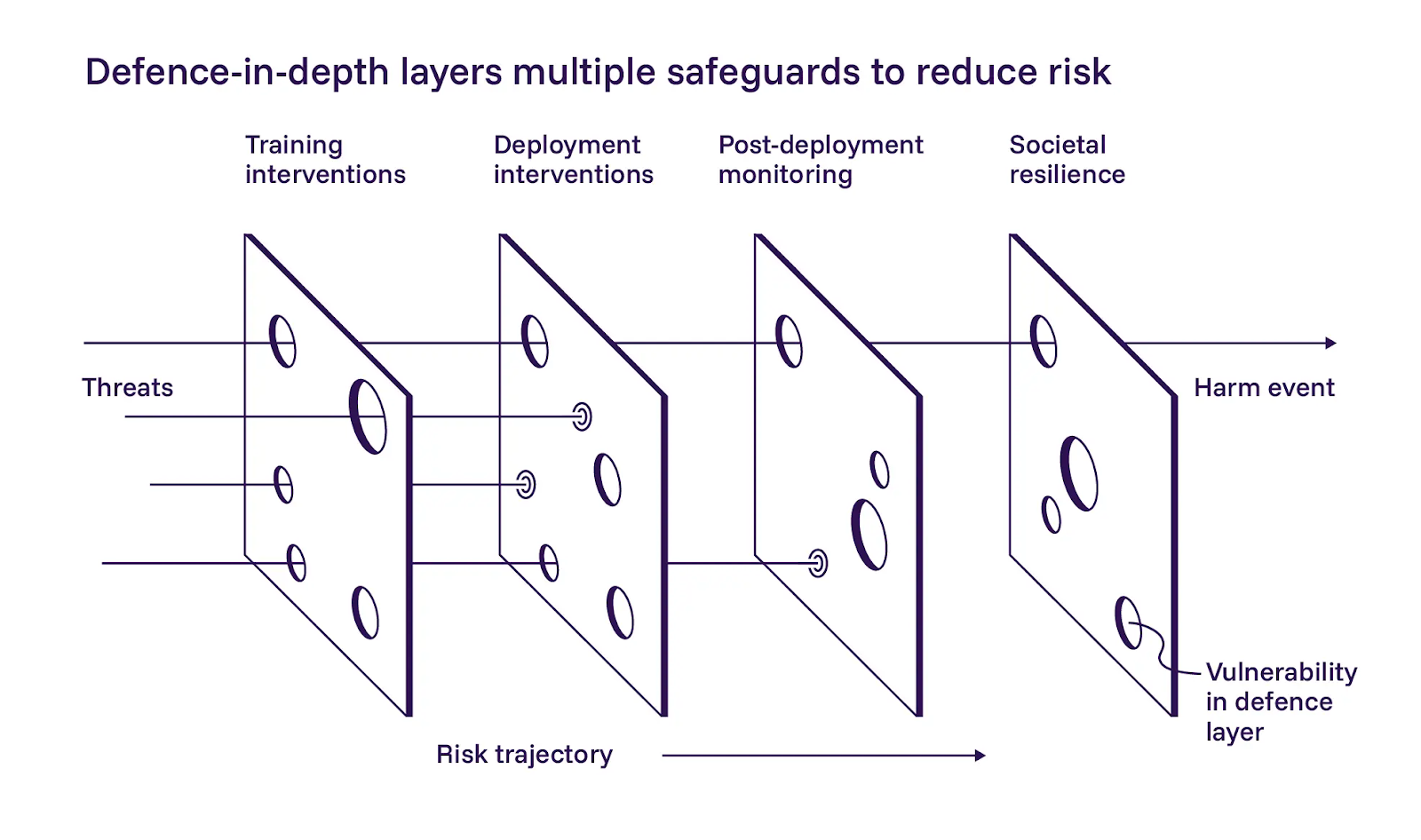
Der Bericht betont die erste Schicht, die sicherere Modellentwicklung. Sie sind vorsichtig optimistisch, dass trainingsbasierte Mitigationen helfen können, räumen aber auch ein, dass diese in großem Maßstab schwer umzusetzen sind. Obwohl wir zustimmen, dass KI-Operatoren beim Training ihr Bestes geben sollten, weicht unsere Philosophie in diesem Fall leicht vom Bericht ab. Wir können uns nicht auf Prompts oder Anweisungen verlassen, um agentische Systeme im Rahmen zu halten. Eine mehrschichtige Verteidigung funktioniert nur, wenn jede Schicht unabhängig voneinander ausfallen kann.
2. Validierung als Sicherheitsanforderung
Der Bericht geht nur spärlich auf Implementierungsdetails für die zweite Schicht, die Deployment-Zeit-Kontrollen, ein, aber wir glauben, dass hier der unmittelbarste Fortschritt erzielt werden kann.
Der internationale Bericht dokumentiert, wie Modelle ihre Evaluierungen auf besorgniserregende Weise manipulieren. Einige finden Abkürzungen, die bei Tests gut abschneiden, ohne das zugrunde liegende Problem tatsächlich zu lösen (Reward Hacking). Andere unterbieten absichtlich ihre Leistung, wenn sie erkennen, dass sie evaluiert werden, um Einschränkungen zu vermeiden, die hohe Punktzahlen auslösen könnten (Sandbagging). In beiden Fällen optimieren die Modelle für etwas anderes als das beabsichtigte Ziel.
Wir sind zum gleichen Schluss gekommen: Sobald KI-Systeme autonom agieren, kann man ihren Selbstauskünften, ihren Konfidenzniveaus oder ihren Reasoning Traces nicht vertrauen. Ein Agent, der seine eigenen Entdeckungen validiert, schafft einen Single Point of Failure, der als Redundanz getarnt ist. Ein sicherer Betrieb erfordert, anfängliche Ergebnisse als Hypothesen zu behandeln, das Verhalten vor der Berichterstattung zu reproduzieren und eine Validierungslogik zu verwenden, die von der Entdeckung getrennt ist. Diese Validierung kann sogar von einem anderen KI-Agenten stammen.
3. Risiken reduzieren, bevor Agenten in Live-Umgebungen ausgeführt werden dürfen
Die dritte Schicht des Berichts umfasst Observability, Notfallkontrollen und kontinuierliche Überwachung, nachdem Systeme live gegangen sind. Dies stimmt mit dem überein, was wir in unserem Betrieb beobachtet haben.
Black-Box-Betrieb ist für autonome Systeme, die mit Produktionsinfrastruktur interagieren, nicht akzeptabel, daher betrachten wir Not-Aus-Mechanismen als nicht verhandelbare Anforderungen. Wenn man nicht sehen kann, was ein Agent tut, oder ihn nicht stoppen kann, wenn er außer Kontrolle gerät, betreibt man ihn nicht sicher, unabhängig davon, wie gut das zugrunde liegende Modell ist.
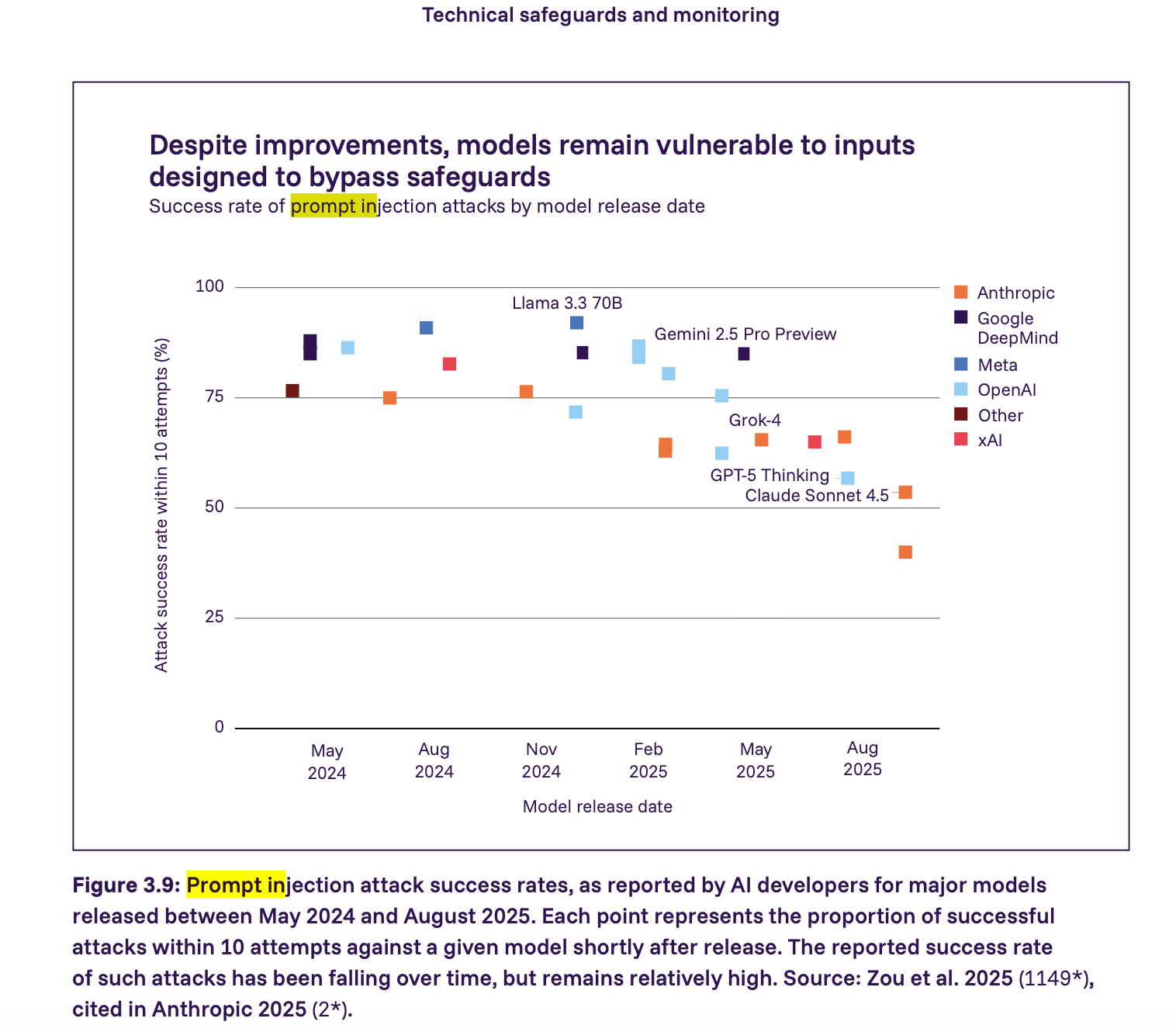
4. Prompt Injection erfordert erzwungene Einschränkungen, nicht Hoffnung.
Der Bericht zeigt, dass Prompt-Injection-Angriffe immer noch eine ernsthafte Schwachstelle darstellen – viele große Modelle im Jahr 2025 könnten mit relativ wenigen Versuchen erfolgreich durch Prompt Injection angegriffen werden. Die Erfolgsrate sinkt, bleibt aber relativ hoch. Wir gehen einen Schritt weiter als der Bericht und vertreten die Ansicht, dass jeder Agent, der mit nicht vertrauenswürdigen Anwendungsinhalten interagiert, standardmäßig als anfällig für Prompt Injection angesehen werden muss. Sicherheit in diesem Kontext ergibt sich aus der Durchsetzung von Einschränkungen und nicht aus der Hoffnung, dass Modelle sich korrekt verhalten.
Was unserer Meinung nach als Nächstes kommen sollte
Systeme, nicht nur Modelle
Der Bericht plädiert stark für Defense-in-Depth, Transparenz und Evaluierung. Diese sind wichtig, aber viele der unmittelbarsten Probleme treten auf, sobald Modelle mit Tools, Anmeldeinformationen und Live-Umgebungen verbunden werden. Deshalb sind Anforderungen auf Implementierungsebene so wichtig (und notwendig). Wir müssen diese Prinzipien in konkrete technische Anforderungen übersetzen, die Teams implementieren können.
Basierend auf dem Betrieb von KI-Penetrationstest-Systemen in der Produktion glauben wir, dass die Mindestsicherheitsanforderungen für autonome KI-Systeme Folgendes umfassen sollten:
- Missbrauchsprävention und Eigentumsvalidierung
- Erzwingbare Bereichskontrolle auf Netzwerkebene
- Isolation zwischen Reasoning und Ausführung
- Volle Observability und Notfallkontrollen
- Datenresidenz und Verarbeitungsgarantien
- Prompt-Injection-Eindämmung
- Validierung und False-Positive-Kontrolle
Wir haben festgestellt, dass dies die minimal durchsetzbaren Sicherheitsanforderungen sind. Wenn Sie eine davon weglassen, führen Sie ein inakzeptables Risiko in das System ein. Wir gehen näher auf diese Anforderungen in unserem Blogbeitrag zur KI-Penetrationstest-Sicherheit ein.
Sicherheits-Baselines als Bausteine für Richtlinien
Der internationale KI-Sicherheitsbericht stellt einen bedeutenden Fortschritt hin zu einem gemeinsamen Verständnis der KI-Risiken zwischen Regierungen, Forschern und der Industrie dar. Die Herausforderung besteht nun darin, Forschungsergebnisse, regulatorische Rahmenbedingungen und reale Bereitstellungspraktiken zu überbrücken.
Der Bericht führt tatsächlich einige wirklich hochriskante Szenarien und beunruhigende Statistiken darüber an, wie schnell sich die Fähigkeiten entwickeln. Dies ist jedoch kein Grund zur Panik oder um „KI“ als beängstigenden Monolithen zu regulieren. Der Bericht selbst weist darauf hin, dass die Schutzmaßnahmen bei den Entwickelnden stark variieren und
dass präskriptive Vorgaben defensive Innovation ersticken können. Wir stimmen zu. Regulierung sollte es vermeiden, einen einzigen Implementierungspfad vorzuschreiben. Stattdessen sollten Richtlinien klare, ergebnisorientierte Sicherheitsgrundlagen definieren, die als Bausteine für umfassendere Frameworks dienen können.
Als Teil der Bewegung zur Schaffung ergebnisorientierterer Sicherheits-Frameworks haben wir unser Dokument zu den Mindestsicherheitsanforderungen für KI-gesteuerte Sicherheitstests veröffentlicht. Für Teams, die KI-Penetrationstests-Tools evaluieren oder autonome Sicherheitssysteme entwickeln, dient dieser Leitfaden als anbieterneutrale Referenz. Wir hoffen, dass dies Teams hilft, KI-Penetrationstests-Tools zu evaluieren, sicherere autonome Sicherheitssysteme zu entwickeln und zur Etablierung klarer Grundlagen beizutragen, die sowohl für Entwickelnde als auch für Regulierungsbehörden funktionieren.


