Statische Anwendungssicherheitstests (SAST) scannen Ihren Quellcode — nicht die laufende Anwendung — um unsichere Codierungsmuster zu finden, bevor sie in Produktion gehen. Es ist eines der frühesten und effektivsten Sicherheitstools, das Sie einem Entwicklungs-Workflow hinzufügen können, da es Fehler dann erkennt, wenn sie am günstigsten zu beheben sind: während Sie Code schreiben.
Was SAST tatsächlich leistet
SAST analysiert Quelldateien und sucht nach Mustern, die auf eine Schwachstelle hinweisen: nicht bereinigte Benutzereingaben in SQL-Abfragen, fehlerhafte Kryptografie, unsichere Authentifizierungsabläufe und mehr. Da es Code statisch (ohne Ausführung) inspiziert, ist SAST hervorragend geeignet, unsichere Codierungspraktiken frühzeitig im SDLC zu erkennen.
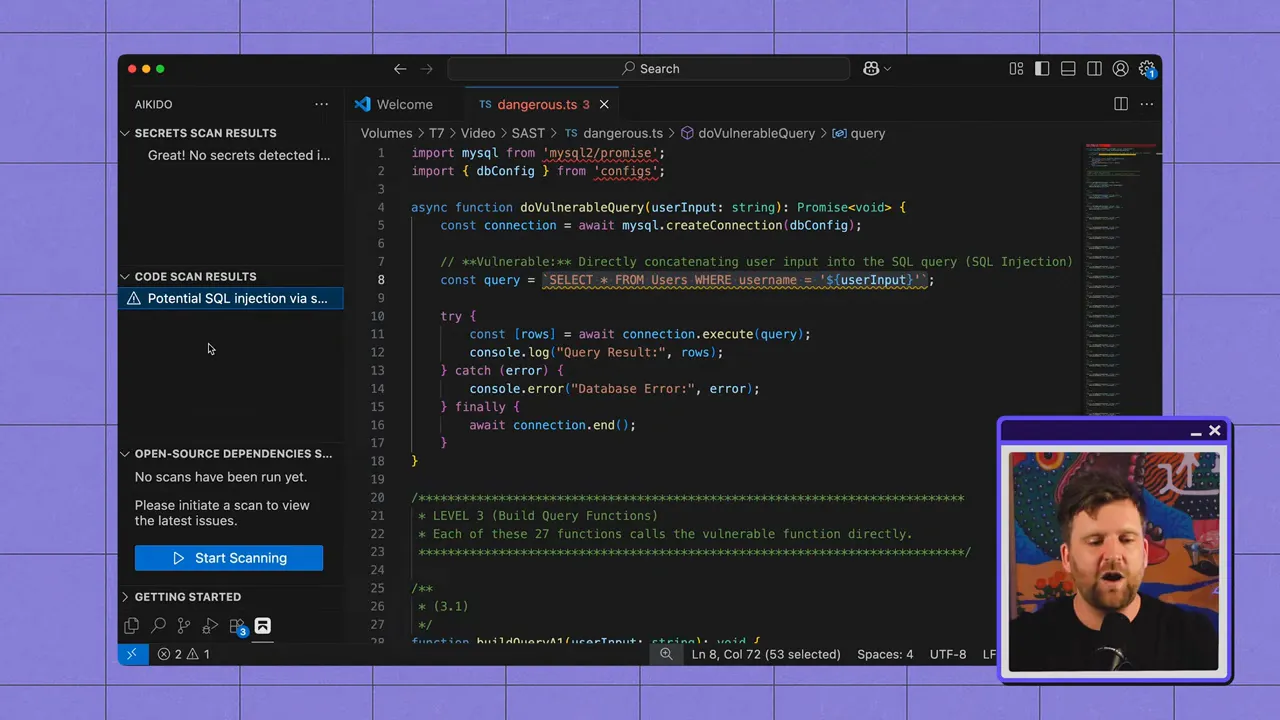
Wo SAST glänzt
- Frühe Erkennung: Läuft in Ihrer IDE oder CI-Pipeline und fängt Fehler vor Staging oder Produktion ab.
- Regelbasierte Abdeckung: Bekannte unsichere Muster (z. B. SQL-Injection-Quellen/-Sinks) können mit gut geschriebenen Regeln zuverlässig erkannt werden.
- Entwickelndenfreundliches Feedback: Integrationen können Probleme im Kontext aufzeigen, sodass Ingenieure sie sofort beheben können.
Ihre Grenzen
- Begrenzter Laufzeitkontext: SAST kann nicht einfach feststellen, ob ein Codepfad in Produktion erreichbar ist oder wie Laufzeitkonfiguration und Abhängigkeiten das Risiko beeinflussen.
- Schwach bei Logikfehlern: Schwachstellen in der Geschäftslogik und komplexe Autorisierungsprobleme sind mit rein statischen Regeln schwer zu erkennen.
- Blindstellen bei Abhängigkeiten und Umgebungen: Schwachstellen, die zur Laufzeit oder über externe Pakete eingeführt werden, entgehen oft der statischen Analyse.
Wie SAST Schwachstellen findet: Regeln vs. KI
Traditionelle SAST-Tools sind überwiegend regelbasiert: Eine Engine parst Code und wendet Tausende von Regeln an, die bekannten unsicheren Mustern entsprechen. Dieser Ansatz ist effizient und präzise für viele Arten von Schwachstellen, da die Muster gut verstanden sind.
“Wenn es um statischen Code geht, kennen wir die Muster, die Code anfällig machen, wirklich.”
Einige Anbieter forcieren KI-gesteuerte Erkennung, aber rohes LLM-Scanning ist tendenziell laut und rechenintensiv — die berühmte Analogie trifft zu: Es ist, als würde man seinen Rasen mit einem Ferrari mähen. Stattdessen besteht der bisher effektivste Einsatz von KI nicht im Scannen an sich, sondern darin, projektweiten Kontext hinzuzufügen, um die Triage und Korrekturvorschläge zu verbessern.
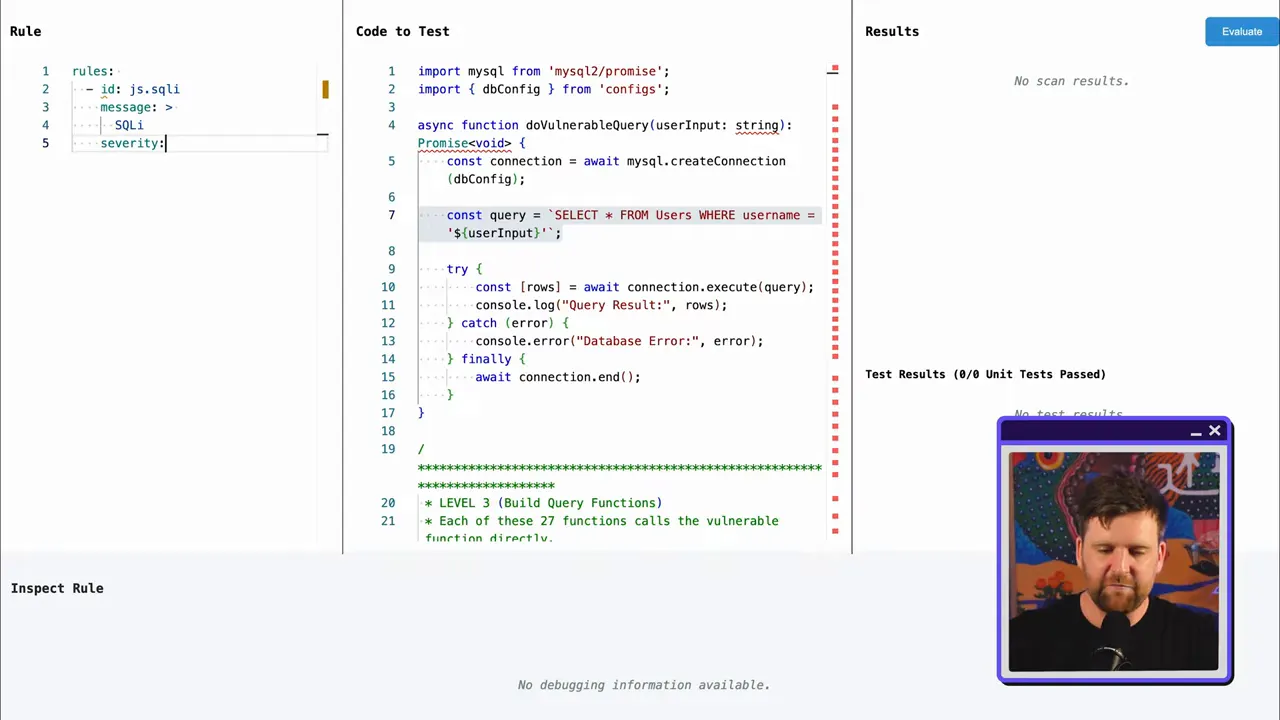
Open-Source SAST in der Praxis: OpenGrep (ein Semgrep-Fork)
Open-Source SAST-Tools sind hervorragende Ausgangspunkte, da sie die Scanning-Engine vom Regelsatz trennen. Die Engine führt Parsing und Matching durch; die Regeln, oft von der Community gepflegt, definieren, was “schlecht” aussieht.
Mit einem Engine-plus-Regeln-Modell können Sie:
- Überprüfen und passen Sie Regeln für Ihre Codebasis an.
- Erstellen Sie projektspezifische Regeln für einzigartige Muster, die kommerzielle Regelsätze übersehen.
- Teilen Sie nützliche Benutzerdefinierte Regeln mit der Community, damit Ihr Team und andere davon profitieren.
Warum False Positives zu einem Reputationsproblem wurden
Regelbasiertes SAST wirft oft ein weites Netz aus. Das ist gut für den Recall – man findet mehr potenzielle Probleme – zieht aber auch viel Rauschen an. Viele markierte Probleme sind in der Produktion nicht erreichbar oder in einem bestimmten Projektkontext sicher, sodass Teams Zeit mit der Untersuchung von Warnungen verbringen, die irrelevant sind.
Stellen Sie sich älteres SAST wie das Fischen mit einem riesigen Netz vor: Sie fangen Fische, aber auch viel Müll. Jemand muss alles durchsortieren, um das Wertvolle zu finden.
Wo KI SAST tatsächlich hilft: automatisches Triage und Auto-Fix
Anstatt regelbasiertes Scannen zu ersetzen, kombiniert modernes SAST-Tooling statische Regeln mit KI-gestützten Schichten, die Kontext hinzufügen und Rauschen reduzieren:
- KI-automatisches Triage: KI-Modelle verarbeiten SAST-Ergebnisse und Projektkontext, um Erreichbarkeit und reale Auswirkungen abzuschätzen. Sie priorisieren die Befunde, die Entwickelnde tatsächlich zuerst beheben müssen (produktionsrelevant, erreichbare Pfade, schwerwiegende Probleme).
- Aufruf-Bäume und Erreichbarkeit: KI kann einen Aufruf-Baum für eine markierte Funktion erstellen und zeigen, wo Eingaben herkommen und wie Daten durch das Repository fließen – was es einfacher macht, festzustellen, ob ein Problem ausnutzbar ist.
- Korrekturvorschläge: KI kann prägnante, umsetzbare Code-Korrekturen vorschlagen (z. B. parametrisierte Abfragen anstelle von string-verkettetem SQL), was die Behebung innerhalb der IDE beschleunigt.

Wo SAST in Ihrem Entwicklungs-Workflow ausgeführt werden sollte
Um den Wert zu maximieren, führen Sie SAST in mehreren Phasen des SDLC aus:
- In der IDE: IDE-Plugins erkennen Probleme, während Entwickelnde tippen, was sofortige Korrekturen und Lernprozesse ermöglicht.
- Im Remote-Repository: Scans im Repository bieten eine einzige Quelle der Wahrheit für das, was ausgeliefert wird. Dies ist unerlässlich, wenn ein IDE-Scan übersehen oder falsch konfiguriert wurde.
- In CI/CD-Pipelines: Automatisierte Scans während des Builds erzwingen Policy Gates und verhindern, dass unsicherer Code in Staging oder Produktion gelangt.

Praktische Empfehlungen für Teams
- Beginnen Sie mit Open Source: Nutzen Sie ein Community-Tool, um zu erfahren, was SAST in Ihrer Codebasis findet und Vertrauen aufzubauen, bevor Sie kommerzielle Tools kaufen.
- Regeln anpassen: Fügen Sie projektspezifische Regeln für Muster hinzu, die einzigartig für Ihren Stack sind; teilen Sie nützliche Regeln mit der Community.
- KI dort einsetzen, wo sie nützt: Nutzen Sie KI-gestützte Triage, um Rauschen zu reduzieren, und Auto-Fix, um die Behebung zu beschleunigen — verlassen Sie sich jedoch heute nicht auf LLMs für rohes Scanning im großen Maßstab.
- An drei Punkten integrieren: IDE für unmittelbare Rückmeldung an Entwickelnde, Repository als Single Source of Truth, CI zur Durchsetzung.
- Messen und optimieren: Verfolgen Sie das Signal-Rausch-Verhältnis, passen Sie Schwellenwerte an und iterieren Sie Regeln und Triage-Modelle, damit Ihr Team dem Scanner vertraut.
Fazit
SAST ist nach wie vor eine der kosteneffektivsten Methoden zur Reduzierung von Sicherheitsrisiken, da es Probleme auf Code-Ebene frühzeitig erkennt. Regelbasierte Engines bleiben die Arbeitspferde für die Erkennung, während sich KI als wertvollste kontextuelle Ebene erweist, die Ergebnisse priorisiert, Erreichbarkeit erklärt und Fixes vorschlägt.
Beginnen Sie klein mit Open-Source-SAST, um herauszufinden, welche Probleme in Ihrem Code existieren. Wenn Rauschen oder Skalierung zu einem Problem werden, fügen Sie KI-gestützte Triage und Auto-Fix hinzu, um eine echte Schwachstellenbehebung zu erreichen — schneller und mit weniger Reibung für Entwickelnde. Testen Sie Aikido Security noch heute!


