KI-Penetrationstests nutzen KI-Agenten, um Anwendungen so zu untersuchen, wie es ein erfahrener menschlicher Tester tun würde. Im besten Fall decken sie IDORs, Autorisierungsfehler und Logik-Missbrauchspfade auf: die schwer fassbaren Fehler, die automatisierte Scanner übersehen und die bei realen Sicherheitsverletzungen auftreten. Die Marketingaussagen übertreffen die Beweise.
Doyensec ist ein unabhängiges Beratungsunternehmen für Anwendungssicherheit. Wir baten sie, einen direkten Vergleich durchzuführen: zwei reale Anwendungen, zufällig aus einem Pool von 442 ausgewählt, in derselben Preisklasse mit denselben Zugangsdaten getestet, wobei jedes Ergebnis von zwei Forschenden manuell validiert und einem Peer Review unterzogen wurde.
Was die Zahlen wirklich aussagen
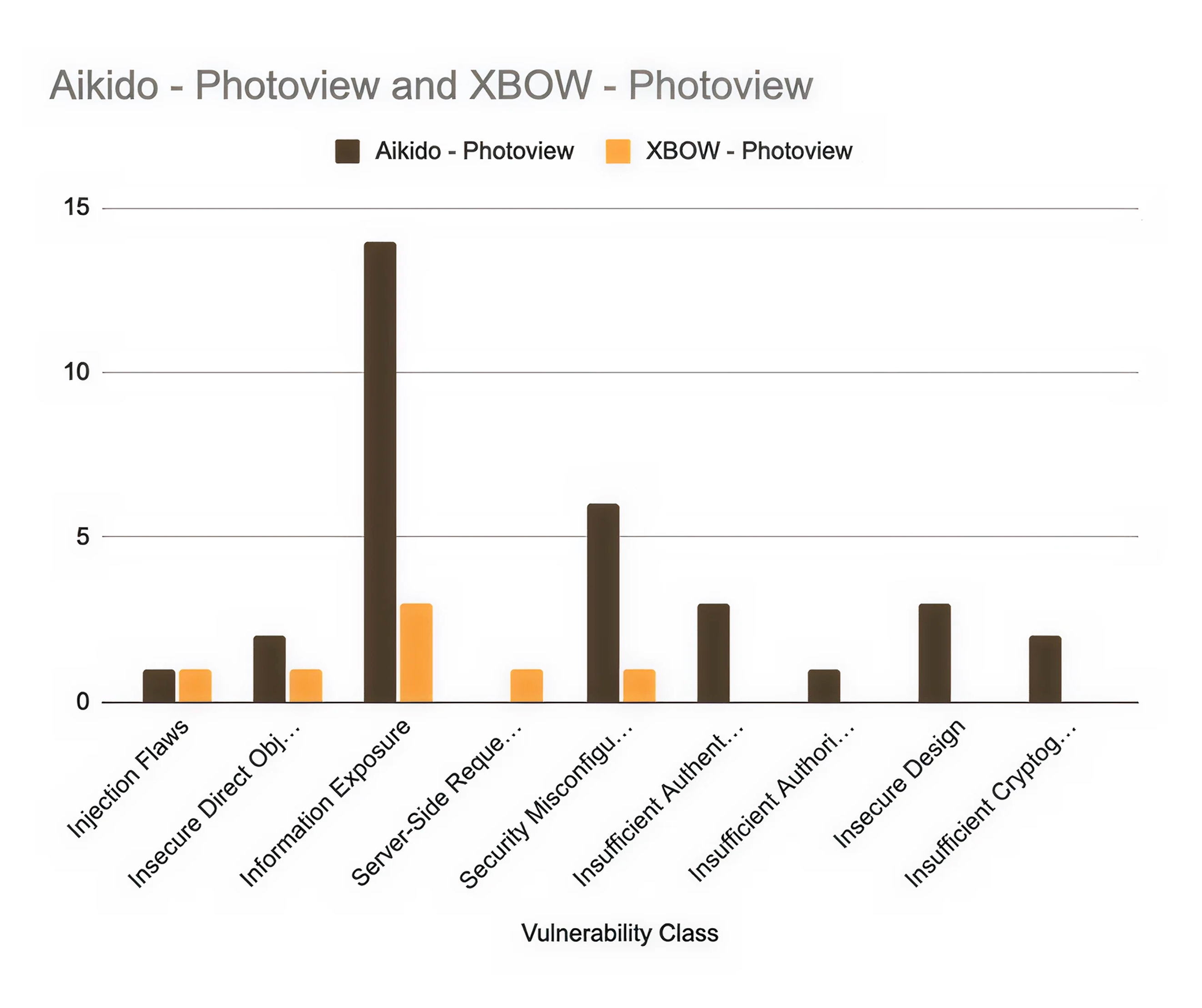
Der Benchmark-Test umfasste zwei Anwendungen: Fider, eine Open-Source-Plattform für Nutzer-Feedback, und Photoview, eine TypeScript/Next.js Fotogalerie-App mit rollenbasierter Zugriffskontrolle.
Aikido deckte 49 verifizierte Schwachstellen auf. XBOW fand 31. Das sind 58 % mehr zum selben Preis.
Quelle: Doyensec
Die False-Positive-Raten sind nahezu identisch. Dies bedeutet, dass der Unterschied nicht darin liegt, dass ein Tool „rauschiger“ oder weniger präzise ist. Beide Tools sind ungefähr gleich kalibriert, aber Aikido findet einfach wesentlich mehr Schwachstellen.
Die Überschneidungsstatistik erzählt die wahre Geschichte: nur 3 übereinstimmende Ergebnisse bei Fider, 4 bei Photoview. Von 49 bzw. 31 Ergebnissen stimmten die beiden Tools bei weniger als 10 % der Schwachstellen überein. Das ist keine geringfügige Abweichung. Zwei Tools, die dieselben Anwendungen untersuchten, fanden fast völlig unterschiedliche Dinge. Die Wahl des Tools hat reale Konsequenzen dafür, welches Risiko Ihnen tatsächlich bewusst ist.
Quelle: Doyensec
Besserer Kontext führt zu besseren Ergebnissen
Aikido analysiert den Code, bevor die Tests beginnen. Jeder Test wird durch das erwartete Verhalten des Codes informiert. Für menschliche Penetrationstester dauert diese Art der Vorbereitung Tage. Für ein KI-System dauert es Sekunden. Die zusätzlichen Kosten sind praktisch null.
Das ist am wichtigsten für die Schwachstellenklassen, die automatisierte Scanner übersehen. IDORs, Autorisierungsfehler und Logik-Missbrauchspfade werden nur sichtbar, wenn man versteht, wie eine Anwendung funktionieren soll. Ein Tool, das einen Benutzer-Endpunkt untersucht, kann nicht wissen, dass dieser Endpunkt mit der ID eines anderen Benutzers zugänglich ist, es sei denn, es versteht, welche Autorisierungslogik durchgesetzt werden soll. Es kann nur sehen, was sichtbar ist. Es kann nicht darüber nachdenken, was unsichtbar sein sollte, es aber nicht ist.
Doyensec stellte auch fest, dass XBOW einen False Positive weniger hatte und in einigen Fällen eine etwas schnellere Validierung der Ergebnisse ermöglicht haben könnte.
Der Teil, über den Käufer erst nachdenken, wenn es ein Problem gibt
Der Umfang ist entscheidend. Was nach dem Start passiert, ist ebenfalls wichtig.
Aikido auf beiden Anwendungen zu konfigurieren und auszuführen, dauerte weniger als 20 Minuten. Self-Service.
XBOW erforderte die Genehmigung durch einen Vertriebsmitarbeiter, bevor der Scan beginnen konnte. Dann einen DocuSign-Vertrag. Als es schließlich lief, waren 22 Support-E-Mails, drei Scan-Neustarts nach Abstürzen, ein gelöschtes Testkonto und zwei Infrastrukturausfälle, die EC2-Upgrades während des Engagements erforderten, nötig. Der Fider-Bericht traf fünf Tage nach Abschluss des Scans und elf Tage nach Beginn des Engagements ein.
Sicherheitsteams führen Penetrationstests unter Druck durch. Elf Tage bis zu den Ergebnissen und Abstürze während des Engagements sind nicht akzeptabel.
XBOW beinhaltet einen erneuten Test innerhalb von 30 Tagen. Aikido bietet unbegrenzte erneute Tests für 90 Tage, ohne zusätzliche Kosten, mit Ergebnissen in Minuten. Der Sinn darin, eine Schwachstelle zu finden, ist, sie zu beheben und die Behebung zu bestätigen. Wenn die Bestätigung jeder Behebung ein neues Engagement kostet, verlangsamt dies entweder den Behebungszyklus oder fügt ein Budget hinzu, das nicht eingeplant war.
Einzelbenutzer-Tests sind für rollenbasierte Anwendungen nicht ausreichend
Xbow unterstützt weder Multi-User-Tests noch Social Login. Für alle, die Anwendungen mit rollenbasierter Zugriffskontrolle testen, ist dies ein großes Problem und führt zu ungetesteten Pfaden.
Ganze Kategorien von Autorisierungs-Schwachstellen erfordern Tests über mehrere Benutzerrollen hinweg. IDORs, Privilege Escalation und Broken Object-Level Authorization werden erst sichtbar, wenn man testen kann, worauf eine Rolle im Vergleich zu einer anderen zugreifen kann. Wenn man nur als ein Benutzer testen kann, sind diese Schwachstellen nicht im Umfang enthalten.
Was Doyensec schlussfolgerte
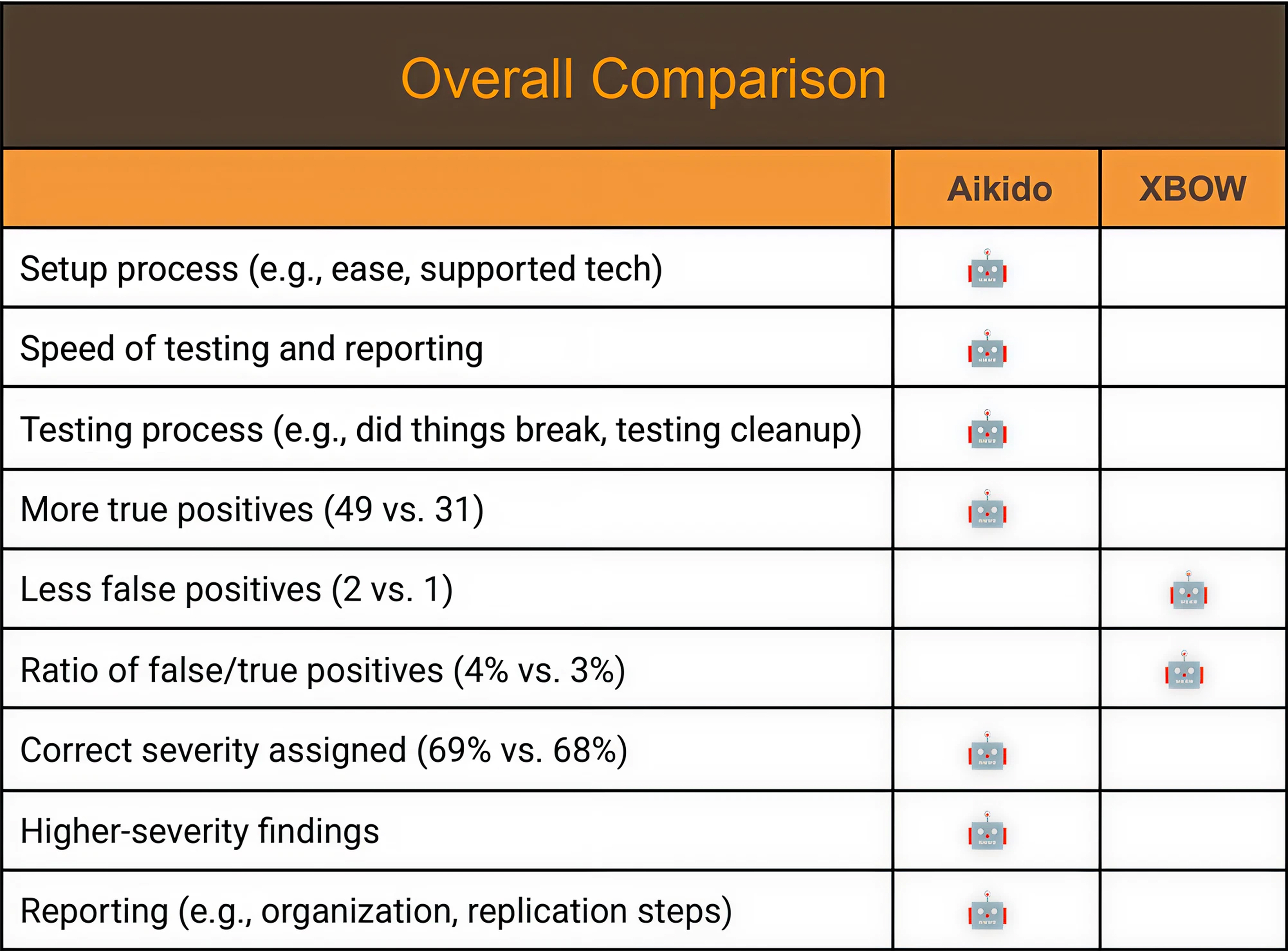
"Aikido zeigte einen Vorteil im Einrichtungsprozess, bei der Gesamtgeschwindigkeit der Tests und Berichterstellung sowie in der Art und Weise, wie sein Testansatz die Zielanwendung und die Umgebung beeinflusste. Es identifizierte auch eine höhere Anzahl von True Positives und lieferte eine etwas stärkere Berichtsqualität."
Wir haben diesen Benchmark in Auftrag gegeben, weil wir dachten, er würde Aikido gut abschneiden lassen. Das tat er auch. Unabhängige Forschung ist nur dann sinnvoll, wenn man die Ergebnisse veröffentlicht.
Der vollständige Bericht mit Methodik, allen Ergebnissen und der Rohdaten-Tabelle ist auf unserer Berichtsseite verfügbar.
Den vollständigen Doyensec-Bericht lesen →
Möchten Sie sehen, was Aikido in Ihrer eigenen Anwendung findet? Demo buchen →


